第8章. 综合性实验1
本章内容首先会讲解如何开展非参数检验,然后会展示几种不同的情况下应该选择何种统计方法。本章中内容主要参考《医学统计学与SPSS软件实现方法》中第7章以及第10章的相关内容。
8.1节. 非参数检验
就像我在《统计方法选择》这个视频中提到的,非参数检验不仅适用于不符合正态分布的定量数据分析,也适用于等级数据的分析。如果了解非参数检验的统计方法就会发现,在非参数检验中关注的是顺序,而不是各项具体的数值。也正因为如此,等级数据只包含顺序,不包含具体数值,自然也可以使用非参数检验来分析。
8.1.1. 与单样本定量数据(符合正态分布)假设检验相对应的非参数检验
可以理解成 小节 5.2 (单样本t检验) 在不符合正态分布前提下的非参数检验版本。
例.1 下表给出了20个人血清抗体滴度值,请判断滴度中位数是否为1:4?
| 滴度值 | 1:2 | 1:4 | 1:8 | 1:16 |
|---|---|---|---|---|
| 频数 | 8 | 4 | 5 | 3 |
与单样本t检验相似,单样本的非参数检验其应用也相对较少,这里简单讲一下如何进行操作。
- 录入数据,如下图所示:
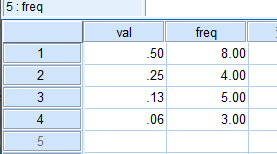
各数据变量视图设置如下图所示

- 频数加权,可参考 小节 7.1 (频数加权)
- 分析 > 非参数检验 > 单样本,打开 单样本非参数检验 对话框
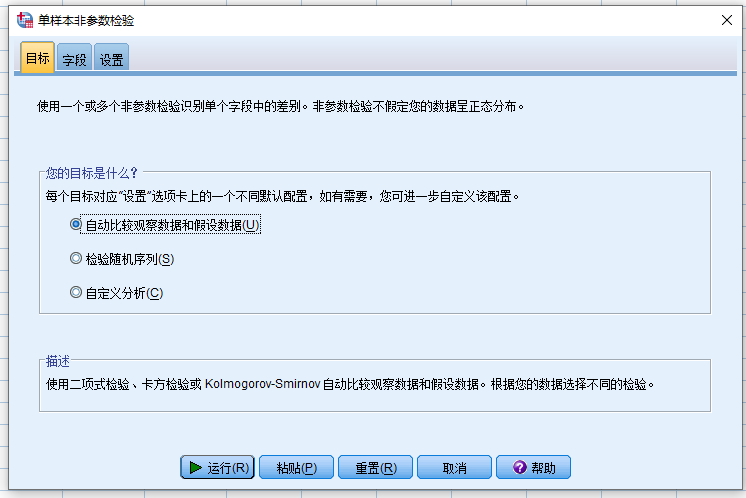
- 点击字段页面,确定 滴度 作为检验字段被选中
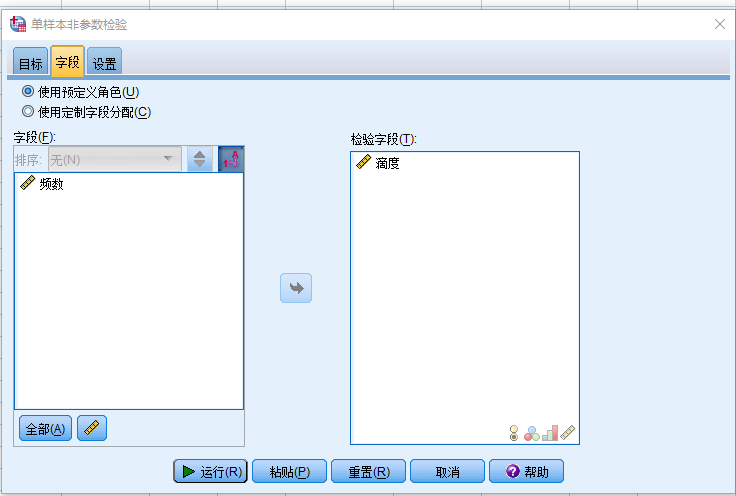
- 点击设置页面
- 选择 自定义检验
- 比较中位数和假设中位数(Wilcoxon符号秩检验)
- 假设中位数:填入1/4,即0.25
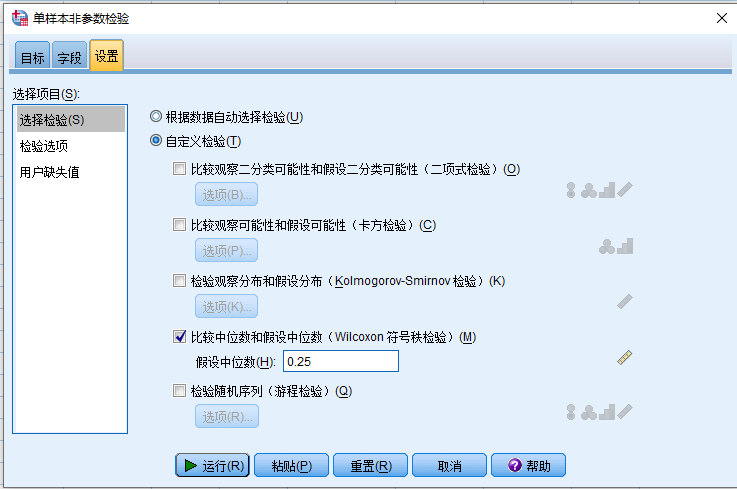
- 选择 检验选项 子页面,确认显著性水平和置信区间符合要求
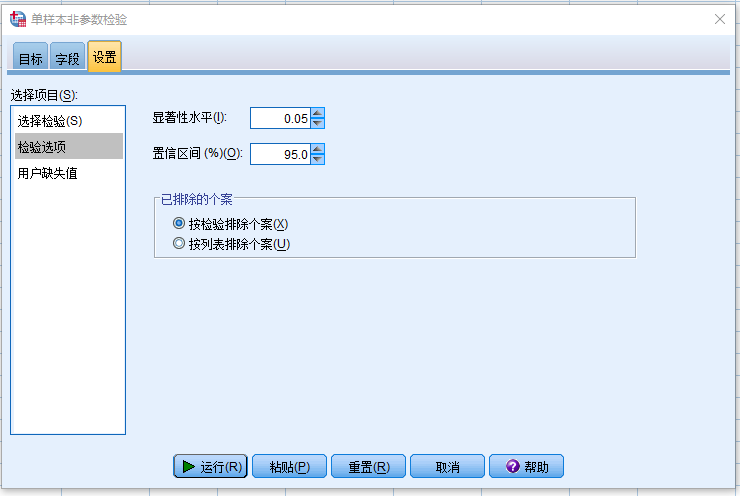
- 选择 自定义检验
- 点击粘贴,获得语法代码
DATASET ACTIVATE 数据集0.
*Nonparametric Tests: One Sample.
NPTESTS
/ONESAMPLE TEST (val) WILCOXON(TESTVALUE=0.25)
/MISSING SCOPE=ANALYSIS USERMISSING=EXCLUDE
/CRITERIA ALPHA=0.05 CILEVEL=95.运行后结果如下图所示

可以看到p值大于0.05(为0.092),不拒绝零假设。
8.1.2. 应对2独立样本的非参数检验
例. 2 数据ch07_1.2_data.sav给出了两组人群(group=1以及group=2)在过去三个月内锻炼的次数。请分析比较两组之间是否存在差异(\(\alpha\)取0.05)
导入数据后,参考 小节 3.3 (正态性检验) 可见,两组数据的分布并不符合正态分布。对于这种数据,原则上应该使用非参数检验。具体操作如下: 1. 获取2组数据的中位数,1/4分位以及3/4分位数: 1. 以grp变量拆分文件,具体操作参考 小节 2.2.2 (拆分) 2. 使用频率工具计算两组样本锻炼次数(exe_times)的四分位数,具体操作参考 小节 3.4.1 (使用频率对话框计算) 或 小节 3.4.2 (使用探索对话框计算) 3. 撤销拆分文件,具体操作参考 小节 2.2.2 (拆分) 1. 分析 > 非参数检验 > 旧对话框 > 2个独立样本
- 打开 2个独立样本检验 对话框
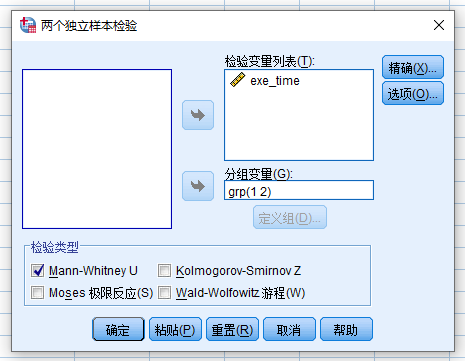
- 变量源列表 (exe_time) > 检验变量列表
- 变量源列表 (grp) > 分组变量
- 点击定义组, 与 小节 5.4 (2独立样本t检验)
相似,这里也需要录入两个组对应的grp值:
- 组1 :1
- 组2 :2
- 点击粘贴获得语法代码:
DATASET ACTIVATE 数据集1.
NPAR TESTS
/M-W= exe_time BY grp(1 2)
/MISSING ANALYSIS.运行后可以获得以下结果:
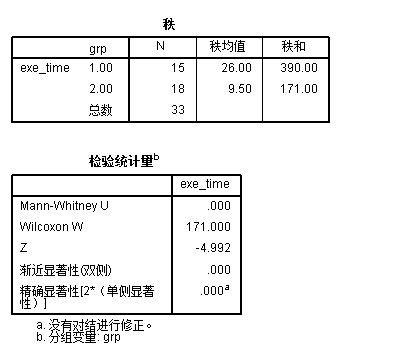
因为在本例数据里面,第一组的所有项都小于第二组,所以Mann-Whitney U值为0,自然渐进显著性(也就是p值)<0.001
对于非参数检验,描述性统计一般按照 中位数(1/4分位 - 3/4分位)数的形式汇报。本例的结果汇报表格如下:

8.1.3. 应对2配对样本的非参数检验
例 3. 对9个水样分别使用重量法(x1)和EDTA法(x2)测定硫酸盐含量,数据见c7_01.csv。请尝试分析两种检测方法是否有区别。
- 参考 小节 2.1.2 (变量视图) 在变量视图中设置变量标签,x1标签为重量法,x2标签为EDTA法
- 参考 小节 3.3 (正态性检验) 对样本两个变量数据正态性作分析,从重量法与EDTA法的箱式图来看,数据呈偏态分布,且具有离群值。因此虽然shapiro-wilk法提示数据符合正态分布(p>0.05),仍考虑使用非参数检验
- 在菜单:分析 > 非参数检验 > 旧对话框 > 2个相关样本 打开对话框,与 小节 5.3 (2配对样本t检验) 相似,也是按照配对关系加入变量,具体操作如下:
- 在变量源列表中点击x1将其选中
- 按下键盘
CTRL键的同时,在变量源列表中点击x2将其一并选中 - 点击右向箭头将其加入 检验对 列表
- 检验类型
- Wilcoxon(W)
- 点击选项,打开两个相关样本:选项对话框
- 统计量
- 四分位数
- 统计量
- 点击粘贴获得语法代码
DATASET ACTIVATE 数据集1.
NPAR TESTS
/WILCOXON=x1 WITH x2 (PAIRED)
/STATISTICS QUARTILES
/MISSING ANALYSIS.运行语法获取结果如下:
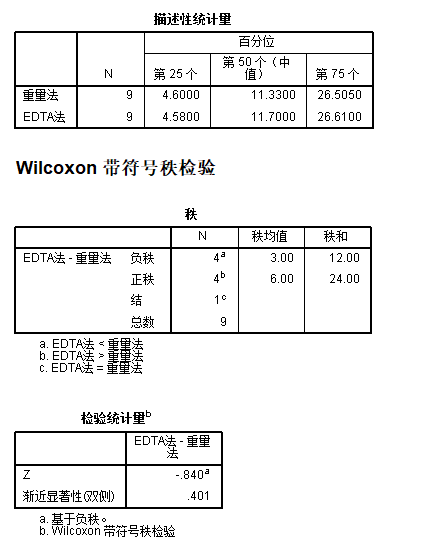
统计结果汇报可参考下表:

8.1.4. 应对多组比较的非参数检验
8.1.4.1. 与单因素方差分析相对应的非参数检验
例 4 某医生为研究慢性阻塞性肺部疾病患者肺动脉血氧分压情况,按肺动脉压的分级标准将44例患者分位3组(1组是 肺动脉血压正常组 ,2组是 隐形肺动脉高压组 ,3组是 肺动脉高压组 ,分别测量肺动脉血氧分压,结果见数据。请问3组患者的血压分压是否有区别?
- csv数据中动脉氧分压的变量名(x)不符合要求,可以重命名为xval。设置变量标签(肺动脉高压,分组),并给分组变量设置值标签,具体方法参考 小节 2.1.2 (变量视图) 和 小节 2.1.2.1 (设置值标签的方法)
- 同样也对三组数据进行正态分布检验。与例3一样,虽然shaprio-wilk检验结果提示三组数据均符合正态分布,但从箱式图以及直方图来看,数据都有负偏态分布的趋势。所以也仍旧使用非参数检验的方法分析
- 获取3组数据的中位数,1/4分位以及3/4分位数,操作方式同 小节 3.4.1 (使用频率对话框计算) 或 小节 3.4.2 (使用探索对话框计算) 所述
- 使用菜单: 分析 > 非参数检验 > 旧对话框 > k个独立样本 打开对话框。具体操作如下:
- 变量源列表 (xval) > 检验变量列表
- 变量源列表 (group) > 分组变量
- 点击定义范围
- 设置最小值为1,最大值为3
- 检验类型
- Kruskal-Wallis H
- 点击粘贴获得语法代码
DATASET ACTIVATE 数据集3.
NPAR TESTS
/K-W=xval BY group(1 3)
/STATISTICS QUARTILES
/MISSING ANALYSIS.运行结果如下:
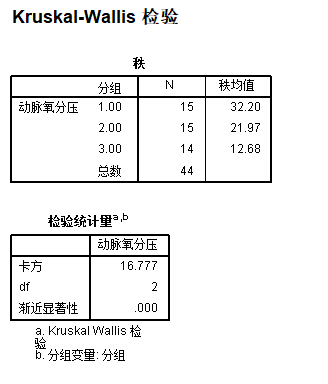
8.1.4.2. 组间相互比较
对于非参数检验来说,spss没有提供像方差分析这样的组间比较工具。与 小节 7.3.4 (组间比较) 相类似的,一般可以利用 Bonferroni 修正 \(\alpha'=\frac{\alpha}{比较次数}\),使用更小的检测水平来避免重复假设检验带来的问题。
而实现的思路也与 小节 7.3.4 (组间比较) 类似,利用筛选功能依次去除1组,2组以及3组,然后比较剩下的两组。自然接下来的比较就从k独立样本变成了2独立样本。
8.2节. 分类变量或等级变量 x 分类变量或等级变量
在开始本节的讲解以前,我们不妨先回顾一下到现在为止,我们所处理数据的各种形式。
- 以数据的形状分类
- 参与统计分析的变量类型
- 组间比较
- 两个配对的定量变量,也就是上面提到的宽数据形式,如
dbp.sav数据- 可以开展的统计分析:配对t检验 小节 5.3 (2配对样本t检验) 与相应的非参数检验 小节 8.1.3 (应对2配对样本的非参数检验)
- 1个分类变量,1个定量变量
- 分类变量为2分类,如
bmi.sav数据比较有无冠心病人群的bmi值- 可以开展的统计分析:2独立样本t检验 小节 5.4 (2独立样本t检验) 与相应的非参数检验 小节 8.1.2 (应对2独立样本的非参数检验)
- 分类变量为多分类,如6-1.sav
- 可以开展的统计分析:方差分析及事后组间比较 小节 6.1 (完全随机设计方差分析) 与相应的非参数检验 小节 8.1.4.1 (与单因素方差分析相对应的非参数检验)
- 分类变量为2分类,如
- 2+个分类变量,1个定量变量
- 一个分类变量属于区别处理因素的自变量,另外一个分类变量属于区组变量,如数据6-2.sav中的group(分组)和block(区组)
- 可以开展的统计分析:随机区组方差分析 小节 6.2 (随机区组设计方差分析)
- 两个分类变量均属于区别处理因素的自变量:如数据6-6.sav中的drug和assay都是处理因素。
- 可以开展的统计分析:析因方差分析 小节 6.3 (析因方差分析)
- 注:2+分类变量 x 不符合正态分布的定量变量:不在本课程讨论之列
- 一个分类变量属于区别处理因素的自变量,另外一个分类变量属于区组变量,如数据6-2.sav中的group(分组)和block(区组)
- 1个分类变量,另外1个分类变量:如第6章的数据中的分组和性别都是分类变量
- 可以开展的统计分析:卡方检验 小节 7.3.1 (SPSS操作流程)
- 1个分类变量,1个等级变量
- 分类变量为2分类
- 可以开展的统计分析:2独立样本t检验对应的非参数检验 小节 8.1.2 (应对2独立样本的非参数检验)
- 分类变量为多分类
- 可以开展的统计分析:方差分析对应的非参数检验 小节 8.1.4.1 (与单因素方差分析相对应的非参数检验)
- 分类变量为2分类
- 两个配对的定量变量,也就是上面提到的宽数据形式,如
- 关联以及一致性
- 2个同样内容的分类变量或者等级变量:如数据9_3_6.sav中的金标准与待评价检测方法,
- 可以开展的统计分析:Kappa系数,McNemar(仅限2个2分类变量时),具体实现方法参考 小节 7.4 (评估者间信度检测)
- 1个定量变量 x 另外1个定量变量
- 可以开展的统计分析:pearson关联系数
- 1个等级变量 x 另外一个等级变量
- 可以开展的统计分析:spearman关联系数
- 2个同样内容的分类变量或者等级变量:如数据9_3_6.sav中的金标准与待评价检测方法,
- 组间比较
在实际研究过程中,是先有研究设计,再有数据收集,最后才作统计分析。以5_4.sav数据为例,该研究属于一项病例对照研究,区分病例组与对照组的关键是有无妊娠期合并症,因此group x bg的分析是符合研究设计的。但在该数据中还额外采集了孕妇年龄是否为高龄这一信息(high_age),high_age x bg这两个变量的组合是否适合开展2独立样本t检验呢?这就要从实验设计的初衷去考虑了。
本节主要就上面提到的1个分类变量,1个等级变量这一大类,以及关联和一致性下面的三种情况作讲解
8.2.1. 分类变量(2分类) x 等级变量
例 5 使用复方中药治疗老年慢性支气管炎患者403例,其中喘息型182例,单纯型221例。具体疗效见下表:
| 疗效 | 喘息型(n=182) | 单纯型(n=221) |
|---|---|---|
| 治愈 | 23 | 60 |
| 显效 | 83 | 98 |
| 好转 | 65 | 51 |
| 无效 | 11 | 12 |
本例中,疗效是等级变量,而慢性支气管炎的分型则是分类变量。改型问题等同于2组独立样本的非参数检验,具体的统计分析方法可以参考 小节 8.1.2 (应对2独立样本的非参数检验) 。在具体操作上需要注意下面几点:
- 疗效的四个等级(无效、好转、显效、治愈)都是文本值,不能直接用来分析,请按照等级1至4作编码录入,当然也要记得设置值标签。在spss中的数据应当是类似下表的形式,也可以打开本题数据作为参考。
| effect | g1 | g2 |
|---|---|---|
| 4 | xxx | xxx |
| 3 | xxx | xxx |
| 2 | xxx | xxx |
| 1 | xxx | xxx |
- 本例数据为宽数据类型,但2独立样本非参数检验需要数据为长数据类型,可以参照 小节 4.2.2.4 (宽数据向长数据的转化) 转化成长数据。具体到本例,两个分组变量下面的值实际上是各种治疗效果的频数,所以目标变量的值就是频数,可以命名为freq,个案组标识可以选用个案号(也可以选择不用个案编号),并将疗效eff作为固定变量
- 对频数变量加权,参考 小节 7.1 (频数加权)
- 宽数据转换成长数据后,记得设置好变量标签以及值标签
- 参考 小节 8.1.2 (应对2独立样本的非参数检验) 做MannWhitney U检验,结果如下:
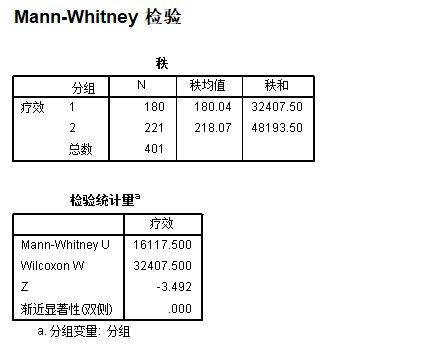
8.2.2. 分类变量(3分类) x 等级变量
例 6 某医院使用三种复方小叶枇杷治疗老年性慢性支气管炎,数据见下表,spss数据见链接,请比较各种方法之间有无统计学差异?
| 疗效 | 老复方 | 复方1 | 复方2 |
|---|---|---|---|
| 控制 | 36 | 4 | 1 |
| 显效 | 115 | 18 | 9 |
| 好转 | 184 | 44 | 25 |
| 无效 | 47 | 35 | 4 |
- 本题数据同样属于宽数据形式,参考前一题进行宽数据向长数据的转换,以及频数加权
- 参考 小节 8.1.4.1 (与单因素方差分析相对应的非参数检验) 做统计分析
8.2.3. 等级变量 x 等级变量,或者分类变量 x 分类变量的一致性分析
例 7 甲乙两位专家同时对200名肿瘤患者的病理切片做分期评定,结果如下表所示,数据见链接,评价两位专家评定结果是否一致
| 乙专家 | 评定 | 结果 | |
|---|---|---|---|
| 甲专家结果 | 低分化 | 中分化 | 高分化 |
| 低分化 | 50 | 10 | 5 |
| 中分化 | 10 | 50 | 15 |
| 高分化 | 10 | 20 | 30 |
- 同样需要将宽数据向长数据转化并设置频数加权
- 参考 小节 7.4 (评估者间信度检测) 计算kappa值并作统计分析
8.2.4. 定量变量 x 定量变量,或者等级变量 x 等级变量的关联性分析
鉴于篇幅所限,本部分内容留待下一章讲解。
8.3节. 习题
- 按照例5的提示说明完成该例题所需的spss操作
- 按照例6的提示说明完成该例题所需的spss操作
- 按照例7的提示说明完成该例题所需的spss操作