第7章. 分类变量的描述性统计与卡方检验
本章主要内容是卡方检验。在讲解SPSS操作以前,不妨先复习一下交叉表卡方检验中各种检验方法的使用细节:
假设现在数据集有20例样本记录,包含两个分类变量:性别(男=1,女=2)与跳绳成绩合格(0=不合格,1=合格),研究者希望了解: 1. 男性与女性跳绳成绩合格率是否存在差异。 2. 性别与跳绳成绩是否合格之间是否相互独立
事实上,上面两个问题是等价的。当我们说 性别
这个分类变量与另外一个分类变量 跳绳是否合格
之间相互独立的时候,我们就是在说不管 性别 取哪一种值,对于
跳绳是否合格
不存在影响,因此也就等价于性别=男与性别=女的两个样本的子集所代表的总体之间,跳绳是否合格
这个变量没有差异,自然的,跳绳成绩合格率也就没有差异。所以:交叉表卡方检验是关于两个分类变量之间的独立性检验。
卡方值的计算公式本身非常简洁:\(\chi^2=\sum{\frac{(O-E)^2}{E}}\),其中O表示每个格子的观测频数,而E表示每个格子的期望频数,自然的,所有格子观测频数的和就是总样本量,即:\(N=\sum{O}\)。不管是本章第二节还是第三节所提到的卡方检验,在具体统计方法的选择中,都遵循:
- 若总样本量 > 40,且期望频数E均 \(\ge\) 5,使用常规卡方检验
- 若总样本量 > 40,但部分格子期望频数E < 5,使用连续型校正。(在SPSS中,连续性校正只能应用于2x2的四格表)
- 若总样本量 < 40,或者20%格子期望频数E < 5,或者存在格子期望频数E < 1,则使用Fisher精确检验。
从上面的细则可以看出来,只有格子数量为4(2x2交叉表独立性检验)或者为2(拟合优度卡方检验)的时候,我们才会按照这三条规则选择统计方法。如果行数或者列数大于2,连续性校正就不适用,于是只剩下1或者3两种方式可供选择。
7.1节. 频数加权
在 小节 4.2.2.4 (宽数据向长数据的转化) ,我们提到了长数据和宽数据的概念。而原始数据,通过统计处理以后,还可以形成 统计数据 ,比如9-7.sav:
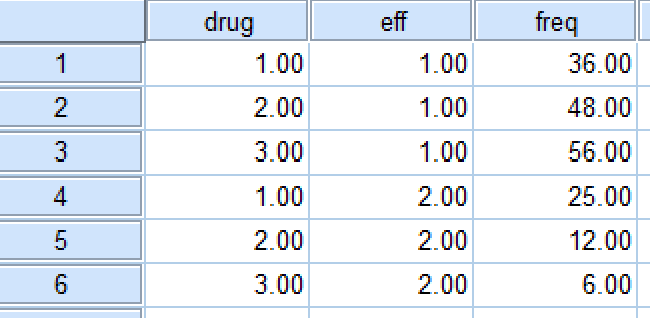
可以看到该数据集包含了三个变量:药物类别:drug,
效果:eff和频数:freq。实际上,只有drug和eff两个变量是来自原始数据,freq是通过对原始数据进行统计(绘制频数表)所得的统计数据。若不进行任何处理,直接进行频数统计,会得到如下结果:
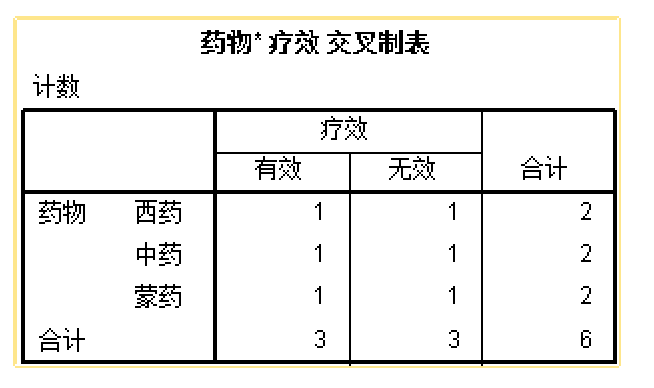
数据集只有6行,所以合计样本量也只有6,这显然是不对的。对于这种数据,必须进行频数加权才能进行后续的各种统计。频数加权的操作步骤如下:
- 数据
- 加权个案
打开 加权个案 对话框
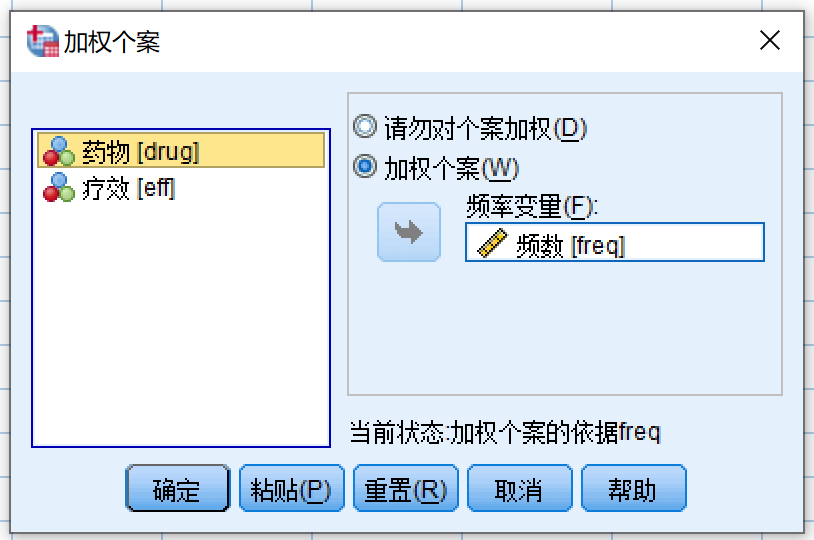
- 选择加权个案
- 变量源列表 (freq) >> 频率变量
点击 粘贴 按钮获取语法代码:
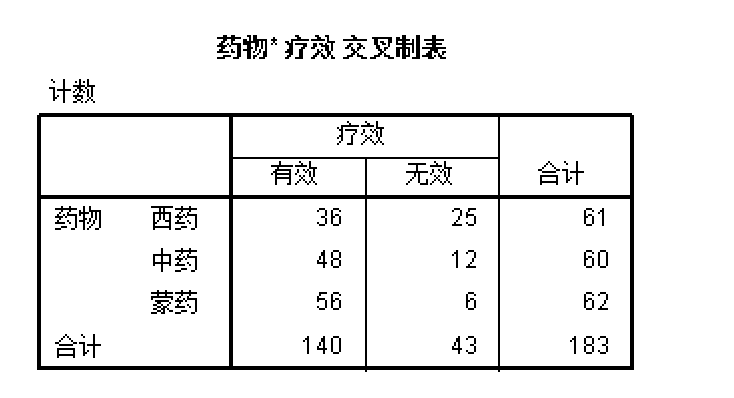
WEIGHT BY freq.运行后再进行频数统计可以看到各行已经按照频数加权了:
7.2节. 拟合优度 (goodness of fit) 卡方检验
例.1 某大学去年对在读学生进行健康调查, 问卷结果提示其中60%的学生没有规律锻炼, 25%偶尔有锻炼, 15%的学生规律锻炼. 随后学校开展了健康促进宣传活动. 一年以后再次做了问卷调查, 访问了470名学生, 得到了下表的结果。请进行分析:经过一年的健康促进宣传,根据问卷的结果来看,学生体育锻炼的频率是否发生了变化?(\(\alpha\)取0.05)
| 分组 | 没有规律锻炼 | 偶尔有锻炼 | 规律锻炼 | 总数 |
|---|---|---|---|---|
| 今年问卷结果显示的学生数 | 255 | 125 | 90 | 470 |
| 一年前问卷结果显示的学生数 | 282 | 117.5 | 70.5 | 470 |
请注意:
- 上表中 一年前问卷结果显示的学生数
各类别的频数,即期望频数E是按照 \[E=N \times
一年前各类别构成比\] 得出的,例如
282=470*60%。 - 事实上本例中的
“分类变量”:锻炼频率严格来说是排序变量,因为从各自代表的锻炼频率来说,显然
规律锻炼>偶尔有锻炼>没有规律锻炼,使用非参数检验更为适宜。本章中暂且忽略这一点,继续将其按照分类变量处理,使用卡方检验。
此类卡方检验的SPSS操作方式:
建立数据集,数据集应包含两个变量:exercise(锻炼频率)以及freq(学生频数)。请尝试自己完成本步骤,若存在困难也可打开参考数据继续后续步骤
进行频数加权,具体参考 小节 7.1 (频数加权)
进行卡方检验
- 分析
- 非参数检验
- 旧对话框
- 卡方
- 旧对话框
- 非参数检验
对话框如下图所示:
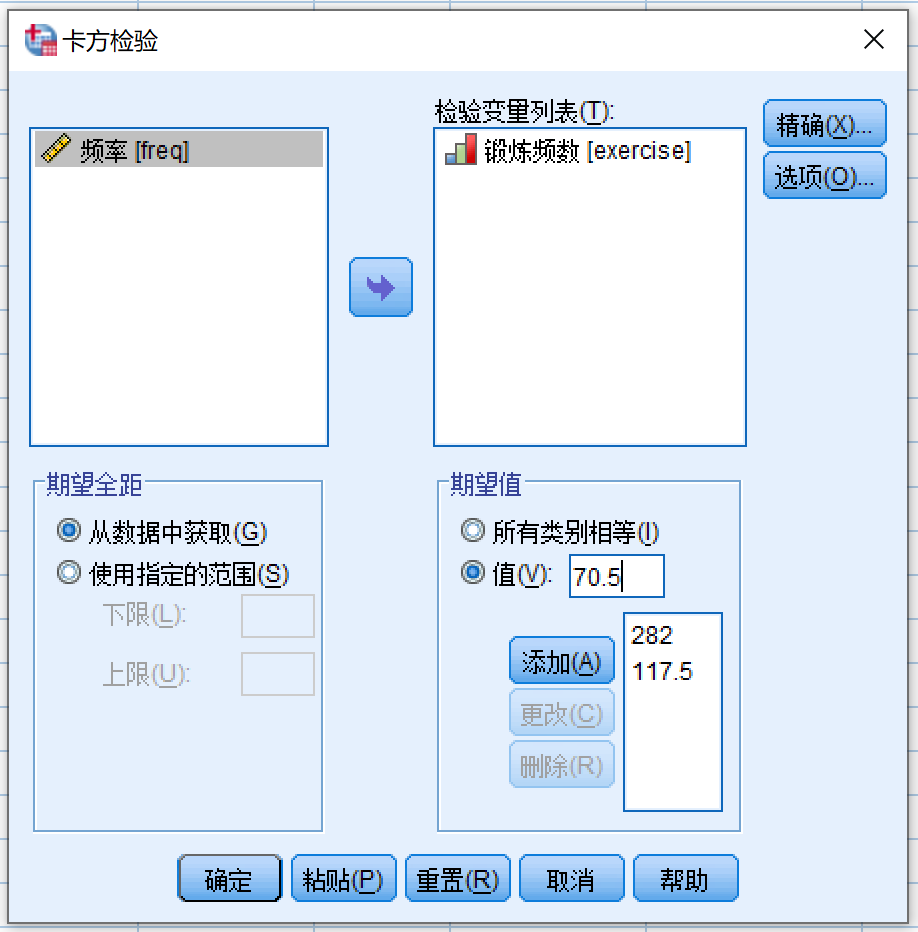
- 变量源列表 (excercise) >> 检验变量列表
- 期望值
- 选择 值
依次按照excercise从1到3所对应的期望频数填入空格:
- 282, 点击添加
- 117.5,点击添加
- 70.5,点击添加
- 选择 值
依次按照excercise从1到3所对应的期望频数填入空格:
- 点击精确
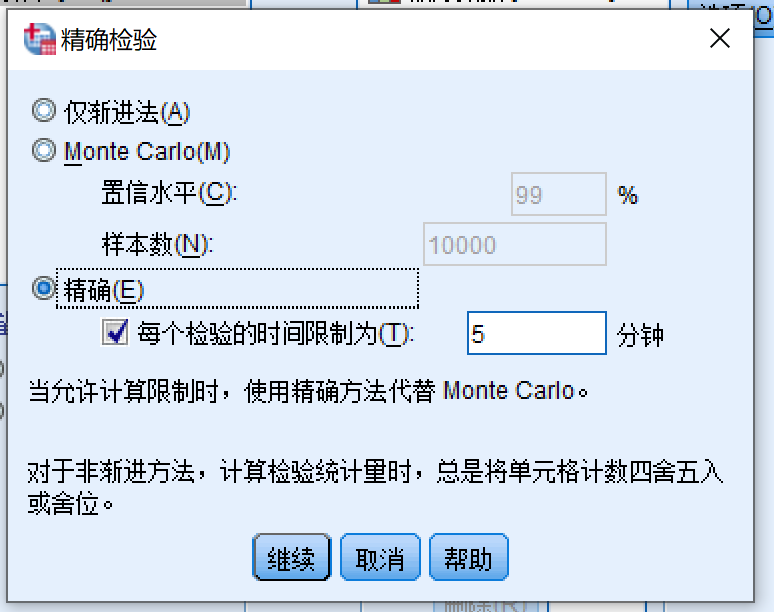
- 在精确检验对话框中:
- 选择 精确
- 点击 继续
- 回到 卡方检验 对话框,点击粘贴 获取以下语法代码:
- 分析
NPAR TESTS
/CHISQUARE=exercise
/EXPECTED=282 117.5 70.5
/MISSING ANALYSIS
/METHOD=EXACT TIMER(5).运行语法后获取以下结果:
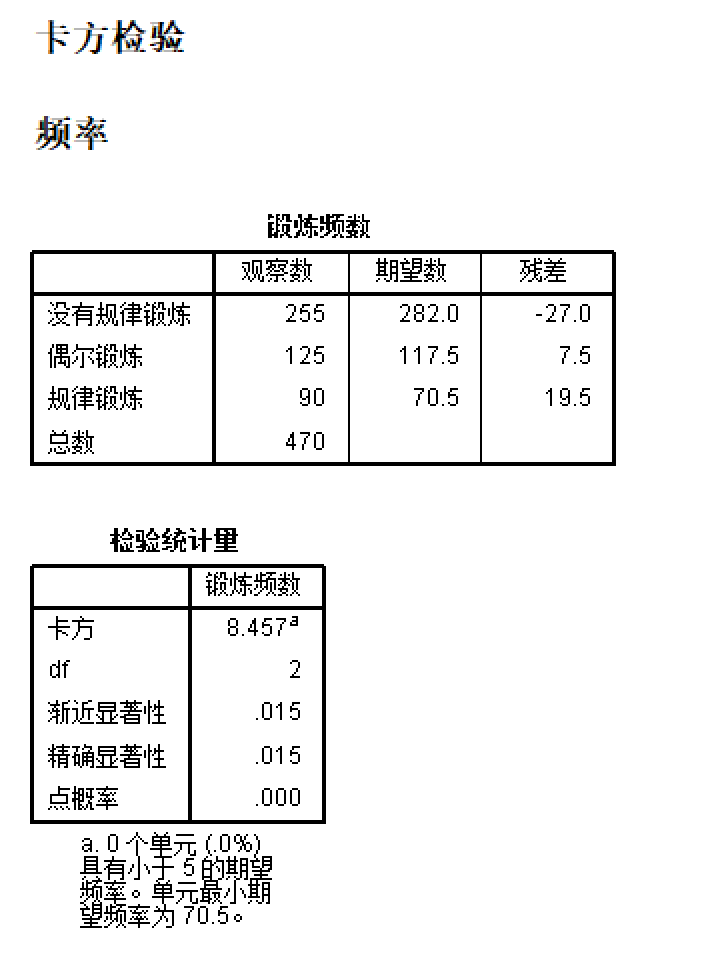
第一个表格可以协助我们检查观察频数以及期望频数是否如题目给出的表格所示,避免录入过程中出现失误。卡方检验的结果在 检验统计量 表格之中,可见\(\chi^2\)为8.457。
卡方检验自由度常规的计算公式是\(df=(R-1)(C-1)\),但在拟合优度卡方检验中没有R的概念,所以\(df=(C-1)=2\)。
渐进显著性是与卡方值相配套的p值,而精确显著性则是使用Fisher精确检验所计算得出的p值,可见两者基本一致。
而在表格后方的标注中,可以看到SPSS检查了是否存在不宜使用卡方检验的情况,由于没有单元格期望值小于5,所以卡方检验是可以使用的。
7.3节. 独立性卡方检验
7.3.1. SPSS操作流程
例.2 研究者开展了一项临床研究,比较两种治疗方案(试验组与对照组)预防某种心血管疾病的效果。同类研究已经显示,男性更容易发生该心血管疾病。为了评价研究对象性别为结果带来偏倚的风险,研究者决定比较试验组与对照组的性别比例。各组受试者性别情况如下表所示,请进行统计分析。(\(\alpha\)取0.05)
| 分组 | 男性 | 女性 |
|---|---|---|
| 试验组 | 30 | 25 |
| 对照组 | 28 | 32 |
上表数据属于宽数据,其中固定变量为分组,男性及女性“变量”下方的各行数值均是频数。
参考 小节 4.2.2.4 (宽数据向长数据的转化) 将宽数据转换为长数据
频数加权,参见 小节 7.1 (频数加权)
卡方检验:
- 分析
- 描述统计
- 交叉表
- 描述统计
打开 交叉表 对话框
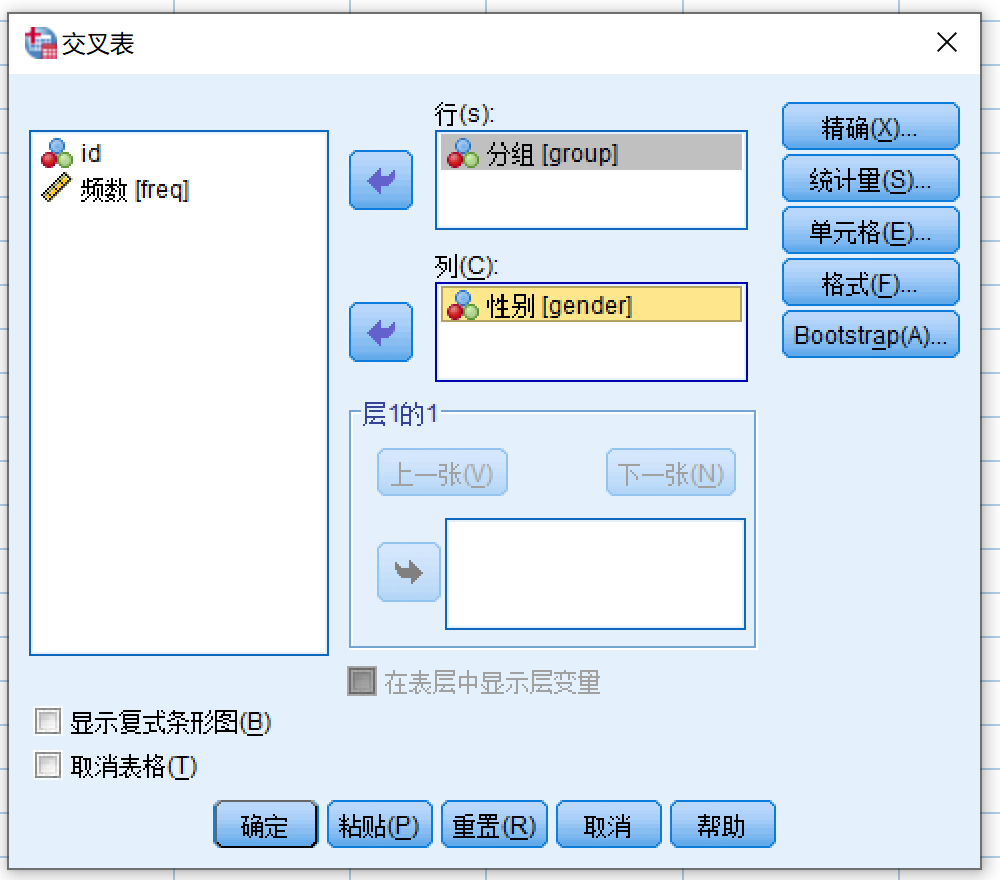
变量源列表 (group) >> 行
变量源列表 (gender) >> 列
点击精确
- 精确检验对话框
- 选择精确
- 点击继续
- 精确检验对话框
点击统计量
打开 交叉表:统计量对话框
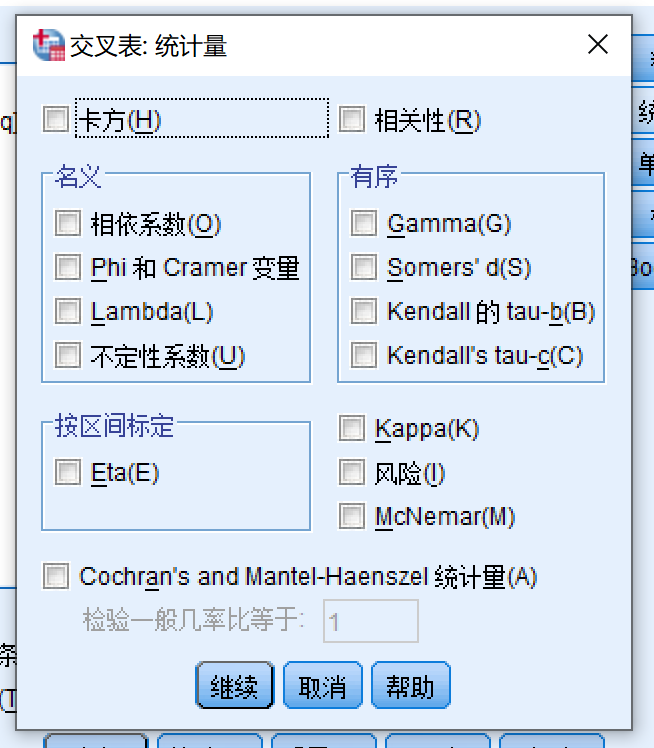
Figure 7.1: 交叉表:统计量 - 卡方
- 点击继续
点击单元格
打开交叉表:单元显示对话框
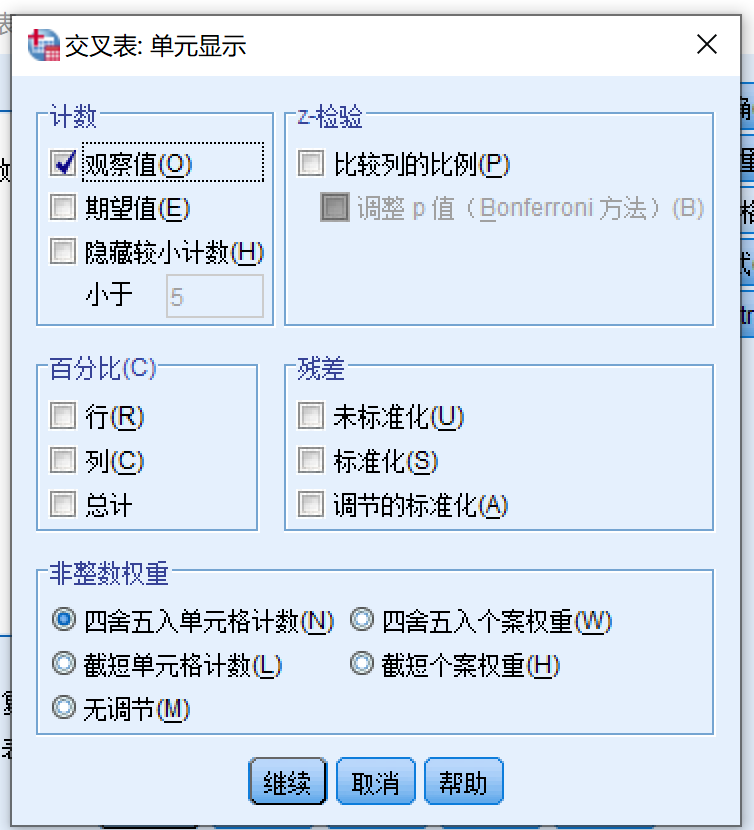
- 计数
- 观察值
- 期望值
- 百分比
- 行
- 列
- 总计
- 点击继续
- 计数
点击粘贴获取语法
- 分析
CROSSTABS
/TABLES=group BY gender
/FORMAT=AVALUE TABLES
/STATISTICS=CHISQ
/CELLS=COUNT EXPECTED ROW COLUMN TOTAL
/COUNT ROUND CELL
/METHOD=EXACT TIMER(5).运行语法后结果如下:
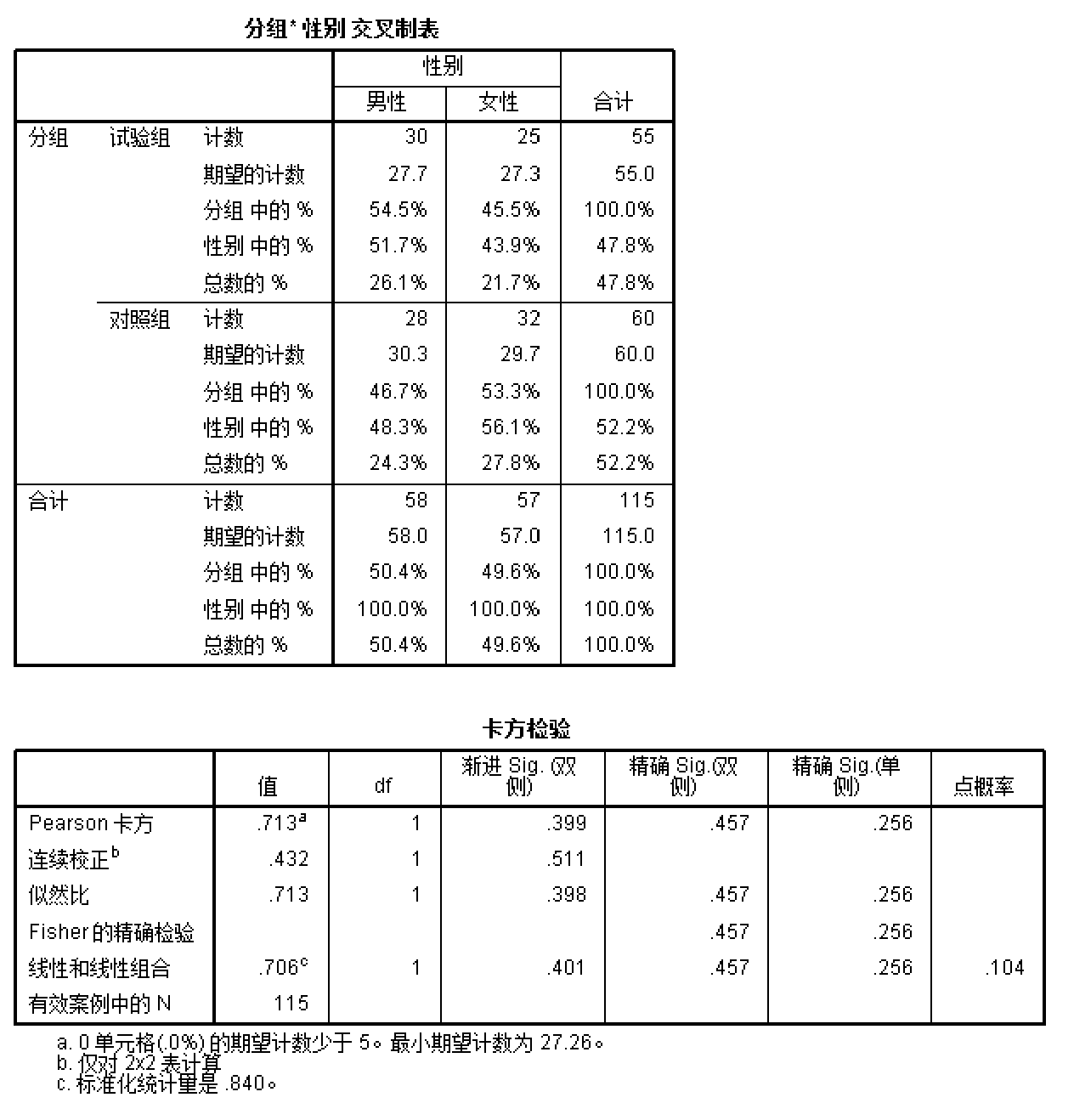
分组*性别交叉制表中展示了四个格子的观测频数(计数),预期频数(期望的计数)。此外还有各个格子占该行及该列的比例,这些比例计算诊断试验准确度的时候会有帮助。
卡方检验表展示了不同检验方法所得出的卡方值。根据总样本量N以及预期频数两个条件,在Pearson卡方,连续校正以及Fisher的精确检验之间选择。
卡方检验表中值一列表示的是统计量,对于Pearson卡方以及连续校正来说,自然统计量就是卡方值。请注意Fisher精确检验没有统计值。df列为自由度,渐进Sig列是使用估算法得出的p值,主要适用于Pearson卡方以及连续校正的情况,而Fisher精确检验所得的p值列举在精确Sig(双侧)一列。
7.3.2. 结果汇报
一般使用统计表进行汇报,以例.2的结果为例: 
对试验组与对照组男女性别比例作卡方检验,结果提示\(\chi^2\)=0.713, p=0.399,故认为两组性别比例无显著差异。
7.3.3. 补充:OR与RR计算
OR(比数比,odds ratio)和RR(相对风险,relative risk)是比较不同因素下出现事件风险的常用描述性统计量。本节将描述如何计算这两个统计量,及其置信区间。
例.3
研究者统计了住院患者中合并心血管疾病(cvd=1)和未合并心血管疾病(cvd=0)患者因新冠肺炎死亡(covid_mort=1为死亡,covid_mort=0为未死亡)的数据,见cvd_covid_mort.sav。请计算合并心血管疾病患者死亡风险与未合并心血管疾病死亡风险的比数比(OR)和相对风险(RR)
- 参考 小节 7.1 (频数加权)
以
freq做频数加权; - 计算OR和RR的方法与 小节 7.3.1 (SPSS操作流程) 的操作相似,但也有需要注意的地方:
相对风险以及比数比计算需要注意的点:
- 自变量放在行,因变量放在列。比如本例中,我们比较合并心血管疾病与未合并心血管疾病的患者因新冠肺炎死亡的数据,故
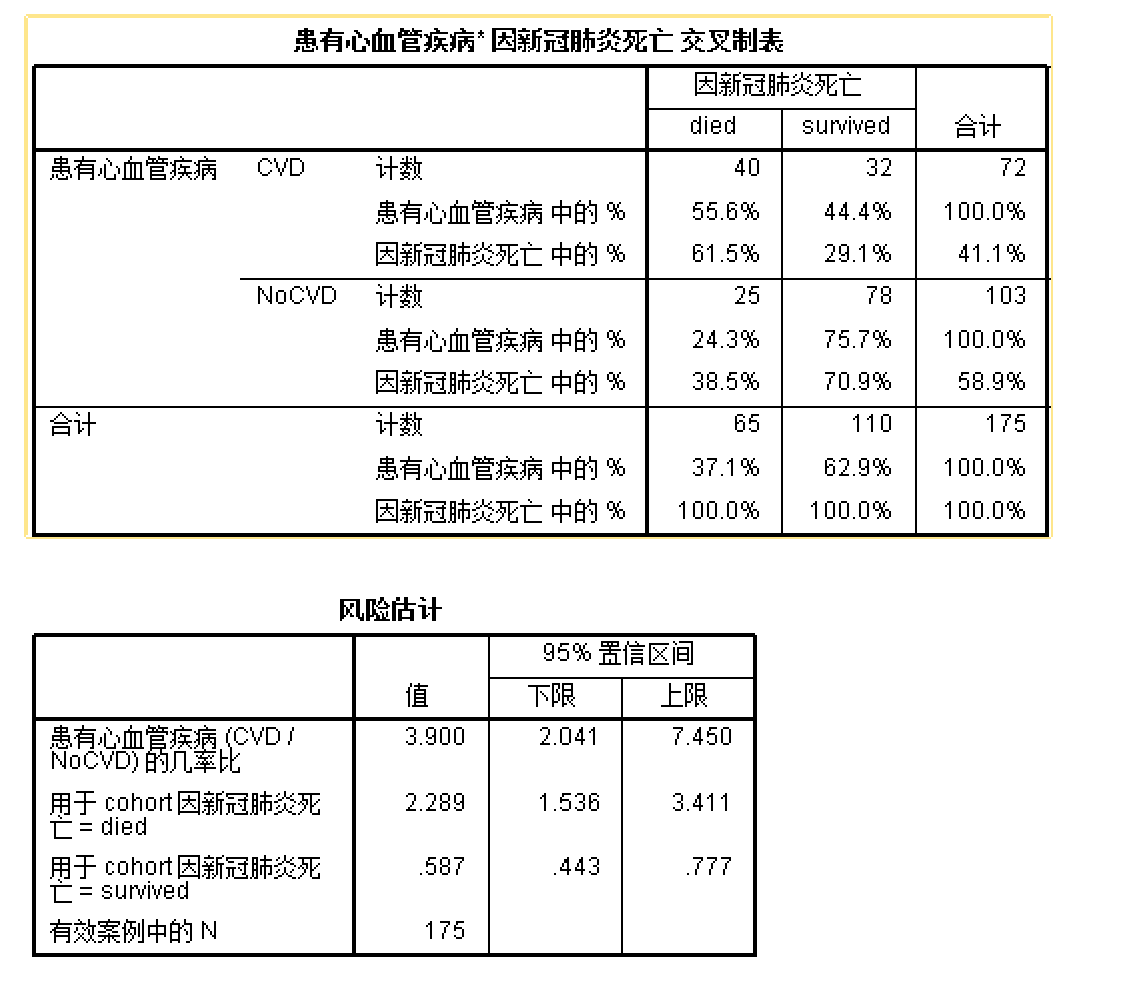
cvd是自变量,covid_mort为因变量 - 在 图 7.1 所示的交叉表统计量中,勾选风险
- 单元格对话框中还是要勾选行和列的百分比,这有助于后面自己验算
- SPSS的风险估算用于2x2四格表
- 请注意该数据的编码方式:有风险暴露(本例中的有冠心病)编码为0,否则为1;出现结局事件(本例中为因新冠死亡)编码为0,否则为1。按照这种编码方式得出的风险估计才是符合需求的。但不管如何,自己用公式验算一下总是好的:
OR计算公式:
\[OR=\frac{暴露出现结局频数/未暴露出现结局频数}{暴露未出现结局频数/未暴露未出现结局频数}\]
出现结局(本例中因新冠死亡)的 RR 计算公式:
\[RR=\frac{暴露样本中出现结局比例}{未暴露样本中出现结局比例}\]
其他操作基本不变。在输出结果中就会出现下面的风险估计表:
7.3.4. 组间比较
由于卡方检验的零假设是行因素和列因素相互独立。因此对于多行多列的交叉表,卡方检验得出阳性结论以后还需要额外将交叉表拆分成多个2x2交叉表进行卡方检验。
例.5
某研究者将两种治疗方法与标准治疗方法相对比,统计治疗的有效率,其结果如ch6_multi_group.sav所示。请进行卡方检验,并进一步分别比较1.
治疗组1与对照组,2.
治疗组2与对照组
卡方检验方法如前所述 小节 7.3.1 (SPSS操作流程) 。在完成3x2交叉表后,需要进一步比较其中两组,这时候需要使用数据筛选,在之前的 小节 2.2.5 (筛选) 已经做了描述。这里再简单讲一下:
- 数据
- 选择个案
在 选择个案 对话框中:
- 选择
- 如果条件满足
- 点击如果
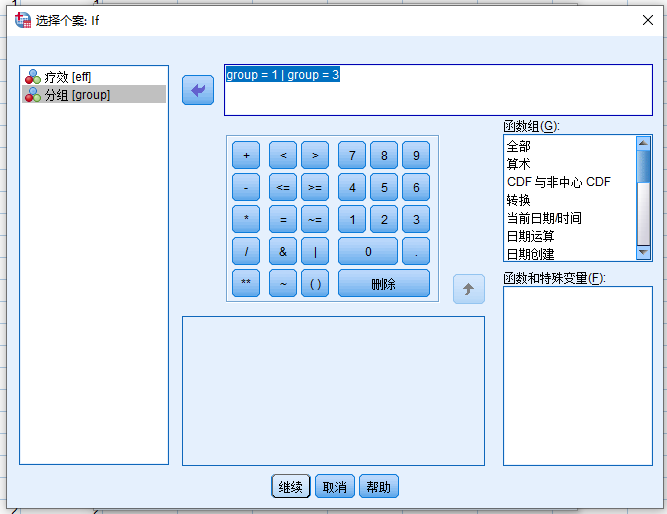
如果需要比较治疗组1(group=1)和对照组(group=3),表达式如图所示:group=1 | group=3,或者也可以使用表达式group ~= 2。
完成筛选后再进行卡方检验,此时只会比较治疗组1和对照组。
请注意,由于做了多重比较,所以需要对一类错误允许水平\(\alpha\)做Bonferroni修正。比如在本例中,我们需要做2次组间比较,因此新的\(\alpha=\frac{\alpha}{2}=0.025\)
7.4节. 评估者间信度检测
评估者间信度检测(inter-rater reliability)是诊断性试验数据统计里一个主要的内容。在实际的临床试验中,经常要面对的一个问题就是:与现在主流的检测方式相比,我要研究的这个新的方式能否做到一样的好?或者说,我的这个新的检测方式获得的结果是否和主流的检测方式(也称作金标准)一致性足够的好,以至于我可以认为新的检测方式是合乎要求的?
本节和下一节都会用下面这个模拟诊断试验数据开展一系列的统计。
例.6 研究者将500例样本分别使用金标准试剂,新型检测试剂(数据中标注为无效试剂)以及新型检测试剂2(数据中标注为模拟试剂)检测。所得出的检测结果见ch6_test_assay.sav。请分别开展mcnemar检验以及计算kappa值,并对结果进行分析。
与之前几节看到的数据不同的是,ch6_test_assay.sav的数据不包含频数变量,而是原始数据,所以不需要进行频数加权。计算mcnemar值以及kappa值的方式是相似的,下面先对金标准试剂和新型检测试剂(标注为无效试剂的test_assay)一对数据进行分析:
- 分析
- 描述性统计
- 交叉表
- 描述性统计
- 变量源列表 (gold_standard) > 行
- 变量源列表 (test_assay) > 列
- 点击统计量 打开 交叉表:统计量 对话框
- Kappa
- McNemar
- 点击继续
- 点击单元格 打开 交叉表:单元显示 对话框
- 百分比
- 行
- 列
- 总计
- 点击继续
- 百分比
- 点击粘贴按钮获得以下语法代码:
CROSSTABS
/TABLES=gold_standard BY test_assay
/FORMAT=AVALUE TABLES
/STATISTICS=KAPPA MCNEMAR
/CELLS=COUNT ROW COLUMN TOTAL
/COUNT ROUND CELL.输出结果如下:
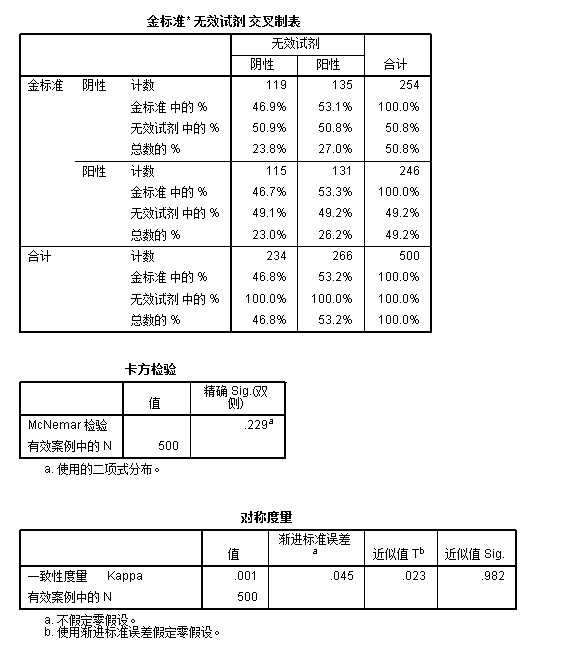
首先从交叉制表中可以看到,无效试剂和金标准之间的一致性是非常差的,金标准阴性的样本中,135例被无效试剂检测为阳性,而金标准阳性的样本中,115例被检测为阴性。也就是说500例样本中有250例(50%)两种检测方式得出的结论是不一致的。照理来说,我们应该得出结论:金标准试剂和无效试剂之间不存在可比性。
但是按照mcnemar值的计算方法:\(\chi^2=\frac{(b-c)^2}{b+c}=\frac{(135-115)^2}{135+115}=1.6\),按照自由度为1,卡方值并不大于临界值,所以无法拒绝零假设,也就是说不能够认为两种检测试剂的结果存在差异。第二个表格卡方检验中汇报的精确sig为0.229,同样大于\(\alpha=0.05\)。
而从对称度量表格中可见,一致性度量kappa值非常小,仅为0.001。一般而言,kappa值在0.7以上才可以认为两种检测方法具备可比性。当然,由近似值sig可得p值为0.982,同样大于\(\alpha=0.05\),不拒绝零假设。
注意:kappa值的零假设是kappa值为0,即两种检测试剂所得结果没有关联性,而mcnemar的零假设是两种检测试剂所得结果无差异,两种统计检测的零假设内涵是完全相反的!
接下来我们再用同样的办法检测一下金标准和新型检测试剂2的一致性。只需要将上面语法中的test_assay改为test_assay2再运行即可
CROSSTABS
/TABLES=gold_standard BY test_assay2
/FORMAT=AVALUE TABLES
/STATISTICS=KAPPA MCNEMAR
/CELLS=COUNT ROW COLUMN TOTAL
/COUNT ROUND CELL.输出结果如下:
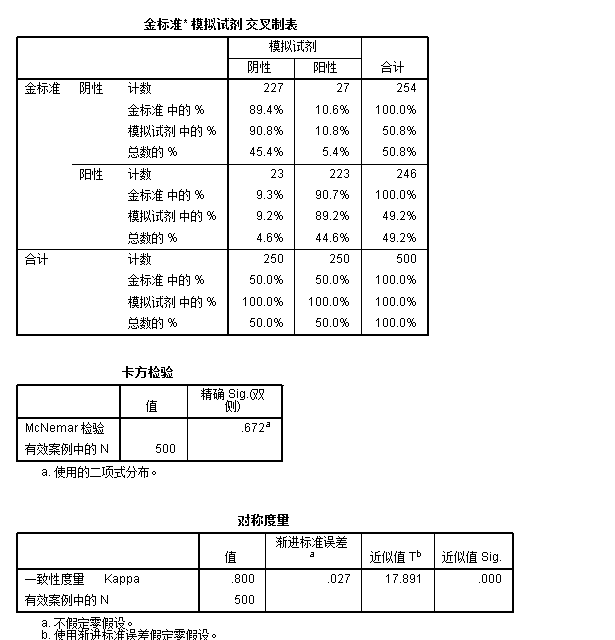
从交叉制表可以看到500例样本中,共227+223=450例样本两种试剂得出一致的结果(占90%),仅有50例相互之间不一致,一致性是非常好的。从mcnemar的结果来看,同样给出了不拒绝零假设的结论,认为两者一致性良好。当然kappa值也给出了同样的结论,其kappa值为0.8,且p值小于0.05。
事实上,在诊断试剂的临床试验中,kappa值是常规使用的统计量,mcnemar则不是,在临床研究中也应注意谨慎使用。
7.5节. 诊断准确性评价指标
诊断试剂的临床试验往往需要汇报包括敏感度,特异度等一系列指标。接下来以 临床诊断 x 金标准 的交叉表为例讲解这些指标应如何获取。
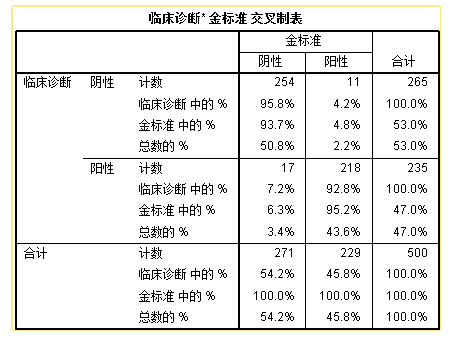
首先要强调的是,敏感度和特异度一般是以最权威的结果作为参照对象,如果有病理诊断则采用病理结果,只有临床诊断则采用临床诊断,若两者都没有,则采用金标准检测手段搜得到的结果。
敏感度即真阳性率:
\(敏感度=\frac{检测试剂阳性且临床诊断阳性数}{临床诊断阳性数}\)
特异度即真阴性率:
\(特异度=\frac{检测试剂阴性数 且 临床诊断阴性数}{临床诊断阴性数}\)
当临床诊断作为交叉表的行变量时,敏感度即检测试剂阳性列在阳性行的占比,即第二行第二列的行百分比:92.8%,可以自行验算92.8%=218/235;而特异度即检测试剂阴性列在阴性行的占比,即第一行第一列的行百分比:95.8%,请自行验算95.8%=254/265。
看完了行方向的占比,接下来再看一下列方向的数据:
\(阳性符合率=\frac{检测试剂阳性 且 临床诊断阳性 数}{检测试剂阳性数}\)
\(阴性符合率=\frac{检测试剂阴性 且 临床诊断阴性 数}{检测试剂阴性数}\)
所以阳性符合率即第二行第二列单元格占该列的列百分比:95.2%,阴性符合率即第一行第一列在该列的占比93.7%
接下来看第五个指标准确度(accuracy):
\(准确度=\frac{检测试剂阳性 且 临床诊断阳性 数 + 检测试剂阴性 且 临床诊断阴性 数}{总样本量}\)
也就是所有检测试剂与实际诊断相符合的例数与总样本量的比,可以将第一行第一列的总数百分比50.8%加上第二行第二列的总数百分比43.6%可得94.4%。
在不同的应用场景中,上面五种指标的名称会有所变化,但是只要弄清具体的计算方式就可以弄明白各种指标的具体含义了。
如果以一个混淆矩阵来表示的话:
| 手动标注区域 | 实际预测 阳性 | 实际预测 阴性 |
|---|---|---|
| 阳性 | TP | FN |
| 阴性 | FP | TN |
敏感度和特异度分别是诊断阳性行中TP所占比例以及诊断阴性行中TN所占比例;阳性符合率与阴性符合率分别是检测阳性列中TP所占比例,阴性符合率则是诊断阴性列中TN所占比例。在机器学习中,阳性符合率又被称为精确度(precision),敏感性则被称为召回率(Recall)
7.6节. 练习题
研究者比较了两种手术方式的术后并发症,其统计结果见ch6_exe1.sav。 1.1 能否使用卡方检验比较观察组与对照组各种并发症发生率是否存在差异?为什么? 1.2 比较观察组与对照组是否发生并发症的概率是否存在差异(发生并发症指:Frey综合征、暂时性面瘫、涎瘘和耳垂区麻木等各种并发症) 1.3 计算两种手术方式术后出现并发症的相对风险度(RR)和比数比(OR)。风险评估的计算方法请参考 小节 7.3.3 (补充:OR与RR计算)
某研究者将腰椎间盘突出症患者1184例随机分为3组,分别用快速牵引法,物理疗法和骶裂孔药物注射法治疗,数据见9_3_4.sav。分析三种疗法是否有不同,并对三种方法进行两两比较。 注:两两比较的方法请参考 小节 7.3.4 (组间比较)
某胸科医院同时用甲乙两种方法测定202份痰标本中的糠酸杆菌,数据见9_3_6.sav,其中
method_a为金标准,method_b为待评估方法: 3.1 使用McNemar \(\chi^2\)值评价金标准与待评估方法是否一致; 3.2 使用Kappa值评价金标准与待评估方法是否一致。mcnemar与kappa值计算方法参见 小节 7.4 (评估者间信度检测) 3.3 计算待评估方法的敏感度,特异度,阳性预测值,阴性预测值以及准确度。计算方法参见 小节 7.5 (诊断准确性评价指标)