第2章. 数据处理与准备
本章目标:学会使用SPSS进行数据导入、变量属性设置,以及常用的数据处理操作(排序、拆分、计算、重编码、筛选)。
建议学习顺序:① 认识SPSS数据文件 → ② 导入/保存数据 → ③ 设置变量属性 → ④ 掌握5种核心数据处理操作。
操作速查表:
操作目标 菜单路径 所在小节 导入Excel/CSV 文件 → 打开 → 数据 2.1.3 设置变量属性 数据编辑器 → 变量视图 2.1.2 保存为.sav 文件 → 保存 2.1.4 数据排序 数据 → 排序个案 2.2.1 分组拆分 数据 → 拆分文件 2.2.2 计算新变量 转换 → 计算变量 2.2.3 重编码 转换 → 重新编码为不同变量 / 自动重新编码 2.2.4 筛选记录 数据 → 选择个案 2.2.5 设置值标签 变量视图 → 值单元格 / 语法 VALUE LABELS 2.1.2 / 2.2.6
2.1节. 打开以及保存数据
2.1.1. 数据文件长什么样子
注:小节 2.1.1 (数据文件长什么样子)及小节 2.1.2 (变量视图)部分视频讲解请参见BV1oa411y7dK
gapminder.sav是一个典型的 SPSS 数据文件,请打开该文件并请关注以下几点:
- SPSS软件一般包含两个主要窗口图 2.1:
- 数据编辑器
- 查看器
- 在本实验系列课程中,我们还会用到第三个窗口:语法编辑器
一般我会习惯将三个窗口利用键盘的windows键(以下简称WIN)加上左右上下方向键快速把三个窗口拼装成下图的样子:
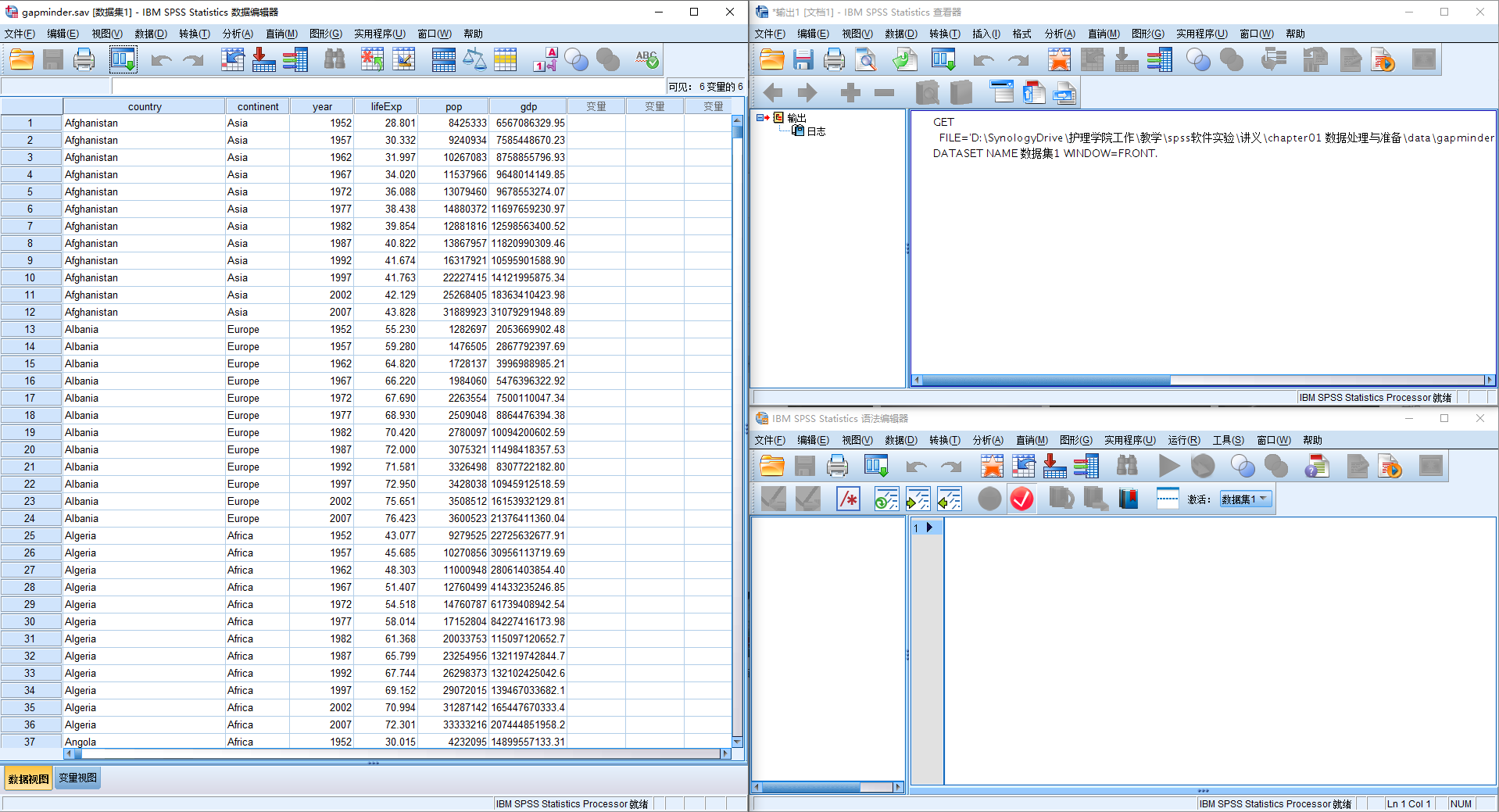
如图,数据编辑器包含两个页面: 数据视图 和 变量视图 ,默认展示的是 数据视图 。可以看到,每个变量的名称写在了各列的顶端:

而每行左侧则是这一行的标识(index):

在很多时候,如果没有具体制定记录的 名称,那么SPSS会默认使用 行标识 作为各个记录的 名称 中间的数据区域与Excel相类似,可以选取,复制,剪切,粘贴以及编辑各个单元格的值。接下来看一下变量视图。
2.1.2. 变量视图
仍以 gapminder.sav 为例,该数据文件的变量视图如下:

每一个变量都具有图中所示的各个属性,比较重要的包括:
- 名称:变量名,不可以包含空格,建议使用英文字母、英文句号、英文下划线和数字这四种字符命名。此外还需要规避一些SPSS保留的名称。
- 类型:基本上, 只有数值类型才能进行统计分析,字符串类型的变量虽然可以按照分类变量处理,但是也建议转换成数值编码。
- 标签:变量的名称是给软件用的,而标签则是给人用的,给变量设置标签可以更好的说明变量的意义。标签支持 中文 。
- 值:给变量的值设置标签。尤其对于分类和排序变量,值标签的设置对结果的解读有很大的帮助。此外,在重编码以后,也应该设置好值标签。
- 度量标准:三种可选标准:
- 度量:对应定量数据,如身高、体重
- 名义:对应分类数据,如性别,分组
- 排序:对应有序数据,如评级
2.1.2.1. 设置值标签的方法
在变量视图中,大部分操作都可以直接在视图表格里完成,但是值标签需要首先点击值的 单元格 ,然后点击 … 按钮,值标签的设置在下面这个对话框里完成:
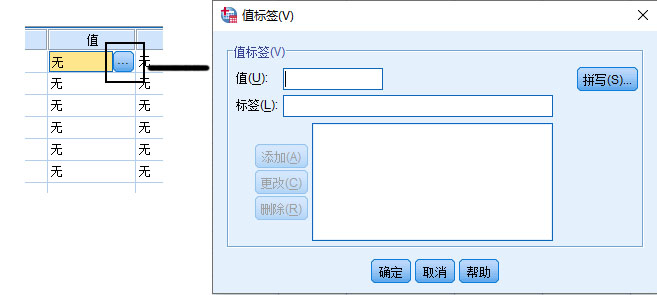
例1.1:假设 age_coded
变量有5个值:1,2,3,4,5,分别表示
10~20岁,20~30岁,30~40岁,40~50岁,50岁及以上,现在在
age_coded 值单元格点出值标签对话框后,应如何操作?
- 设置值1的标签为10~20岁:
- 值(U): 1
- 标签(L): 10~20岁 点击 添加(A) 按钮
- 设置值2的标签为20~30岁:
- 值(U): 2
- 标签(L): 20~30岁 点击 添加(A) 按钮
对3,4及5等值的操作以此类推。
2.1.3. 导入数据
注:本部分视频讲解请参见BV1DS4y1G7iP
2.1.3.1. 导入Excel数据
功能:将Excel格式的数据(.xls, .xlsx, .xlsm)导入SPSS并保存为.sav格式。
菜单路径:文件 → 打开 → 数据(A)…
详细步骤:
- 在弹出的 打开数据 对话框中:
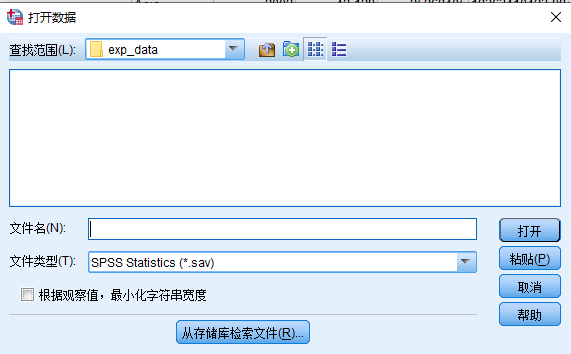
- 文件类型(T): 选择 Excel (.xls, .xlsx, *.xlsm)
- 查找范围(L): 找到数据所在的目录
- 双击需要打开的文件
- 打开Excel数据源 对话框:
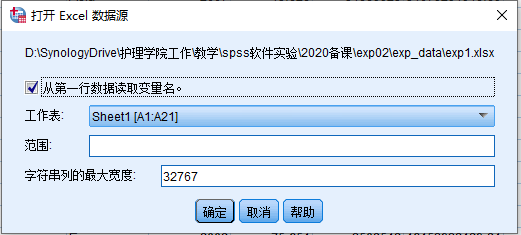
- 从第一行数据读取变量名
- 工作表: 选择Excel数据中所在的工作表,一般默认使用Sheet1
- 点击 确定 按钮
- 将导入的数据保存成
.sav格式的数据文件小节 2.1.4 (数据存储)
在某些情况下,会出现打开后的数据文件内容为空的情况。这个时候可以用WPS或Excel等软件打开数据文件,再将文件中的数据内容通过复制粘贴的方式拷贝进SPSS的数据编辑器内
2.1.3.2. 导入csv等文本数据
功能:将CSV或其他文本格式的数据导入SPSS。
菜单路径:文件 → 打开 → 数据(A)…
详细步骤:
- 在 打开数据 对话框(图 2.6)中:
- 文件类型(T): 选择 所有文件(
*.*) - 查找范围(L): 找到数据所在的目录
- 双击需要打开的文件
- 文本导入向导- 第1步,共6步 对话框,点击 下一步
- 文本导入向导- 第2步,共6步 对话框:
- 变量是如何排列的?: 选择 分隔(D)
- 变量名称是否包含在文件的顶部?: 正常的数据文本文件的第一行是表头,所以选择 是
- 点击 下一步
- 文本导入向导- 第3步,共6步 对话框:
- 如何表示个案?: 选择 每一行表示一个个案
- 你要导入多少个个案?: 选择 全部个案
- 点击 下一步
- 文本导入向导- 第4步,共6步 对话框:
- 变量之间有哪些分隔符?
- 制表符(T):csv的全称是 comma separated values, 默认各列以逗号(comma)分隔,一般不选择制表符
- 空格(S):同理,一般不选择空格
- 逗号
- 分号(E)
- 文本限定符是什么?:具体根据实际情况选择,一般可以选择 无
- 点击 下一步
- 文本导入向导- 第5步,共6步 对话框: 设置各列的变量名称。如前所述,SPSS有若干的保留变量名,如果导入的变量名与之相重合的时候程序会报错,可以尝试更改 变量名称(V)。
- 文本导入向导- 第6步,共6步 对话框: 点击 完成
- 在变量视图中检验导入的各个变量的名称、类型以及度量标准,并设置变量标签和值标签。
- 将导入的数据保存成
.sav格式的数据文件,参考小节 2.1.4 (数据存储)
2.1.4. 数据存储
功能:将当前数据保存为SPSS原生格式(.sav)或其他格式,便于后续直接打开使用。
菜单路径:文件 → 保存(或 另存为)
操作步骤:在 将数据保存为 对话框中:
- 文件名(N):输入文件名
- 保存类型:默认为SPSS数据文件(*.sav),也可以选择其他类型(如Excel文件)
- 点击 保存
2.2节. 数据处理
注:本部分视频讲解请参见:BV1jY411L7HN
本节导读:数据处理是统计分析前的必要准备。本节介绍的5种核心操作(排序、拆分、计算、重编码、筛选)在后续各章都会反复用到,建议结合例题动手练习。
每种操作都统一按以下格式讲解:功能 → 菜单路径 → 操作步骤 → 示例 → 对应语法 → 关键要点。
2.2.1. 排序
功能:按照一个或多个变量的值对数据记录进行升序或降序排列。
菜单路径:数据 → 排序个案
操作步骤:打开 排序个案 对话框(图 2.8),按以下方式设置:
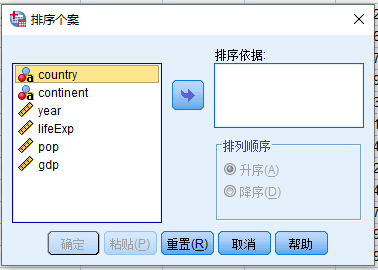
例1.2 将gapminder.sav数据文件优先按照年份(year)升序(从小到大)排列,进一步的,按照预期寿命(lifeExp)降序(从大到小)排列
- 变量源列表 (year) > 排序依据
- 排序顺序:选择 升序(A)
- 变量源列表 (lifeExp) > 排序依据
- 排序顺序:选择 降序(D)
- 点 确定 按钮可以立即排序,而如果我们点 粘贴按钮则可以把实现这种排序的语法粘贴入语法窗口,具体的语法如下代码块 2.1:
语法代码 2.1: 数据排序的语法代码
DATASET ACTIVATE 数据集1.
SORT CASES BY year(A) lifeExp(D).语法说明:
- 上面语句的第一行是激活数据文件。如果我们注意看之前数据编辑器的截图图 2.1 ,在数据编辑器左上角除了
gapminder.sav这个文件名,还有数据集1这样的字样。如果我们打开了多个数据集,可以依靠这个标识区分不同的数据集 - 排序的语法首先是
SORT CASES,而BY的后面跟着的则是变量的名称。请注意每个变量后面跟着一个括号,里面表示按升序((A)),还是降序((D)) - 请注意每一个语法语句的末尾都会有一个 英文的句号作为结束
- 语法不区分大小写
- 请注意语法的各个单词之间有 空格
- 运行 语法的方式很简单:需要运行的语法代码,点击语法编辑器图 1.3中的绿色三角形
思考题:如果我要首先按照年份升序排列,再按照人口升序排列,上面的语法应该如何更改?尝试自己编写语法,然后使用 排序个案 对话框按照前述的操作对数据文件进行排序,点击 粘贴 按钮生成语法,看一下自己写的是否正确。
2.2.2. 拆分
功能:按照某个分类变量的值将数据分组,后续的所有统计分析都会按组分别输出结果。
适用场景:当需要按某个类别(如性别、地区、实验分组)分别查看统计结果时使用。
菜单路径:数据 → 拆分文件
操作步骤:打开 分割文件 对话框(图 2.9),按以下方式设置:
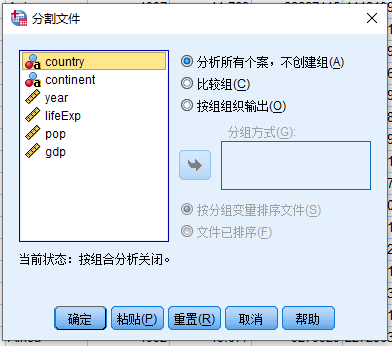
例1.3 按照记录所在的大洲(continent)进行分组,统计各大洲人口最大值
分割文件:
- 选择 比较组(C)
- 变量源列表 (continent) > 分组方式
- 如果要按照continent对数据文件进行排序,可以选择 按分组变量排序文件
- 点 粘贴 按钮可以看到生成的语法:
语法代码 2.2: 拆分文件
SORT CASES BY continent. SPLIT FILE LAYERED BY continent.第1行的
SORT CASES我们刚刚在排序中代码块 2.1见过,出现这一句是由于在分割文件的第3步我们选择了 按分组变量排序文件。 第2行的SPLIT FILE是分割文件的语句,分割文件的两种形式 比较组 和 按组组织输出 分别对应的是LAYERED和SEPERATED, 而BY后面的则是变量名计算最大值: 在进行分割文件以后,从数据编辑器和输出窗口里都看不出什么变化,所以接下来我们提前用一下下一章的内容,展示一下分割文件对后续的分析产生的影响。这里使用描述性统计的频率来计算最大值,通过以下菜单操作打开频率对话框:
- 分析
- 描述统计
- 频率
- 描述统计
- 变量源列表 (pop) > 变量
- 点击 统计量(S) 在 频率:统计量
对话框中:
- 离散
- 最大值
- 点 继续 按钮
- 离散
- 显示频率表格
- 点 粘贴 按钮
于是生成以下语法:
语法代码 2.3: 获取最大值
FREQUENCIES VARIABLES=pop /FORMAT=NOTABLE /STATISTICS=MAXIMUM /ORDER=ANALYSIS.具体语法的讲解留到下一章,这里先看一下运行以后的效果,从输出窗口可以看到:
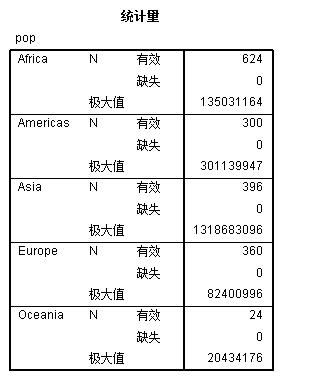
这样我们就分别统计了各个大洲中人口这个变量的最大值
- 分析
思考题:尝试 按组组织输出 分割文件,之后统计各大洲的人口最大值,看一下与 比较组 形式的分割,结果有什么不同
请注意,进行拆分文件操作以后,当前数据文件会一直保持拆分的状态,只有在 分割文件 对话框中图 2.9选择 分析所有个案,不创建组 才能取消拆分。具体操作只需要在 分割文件 对话框中选择 分析所有个案,不创建组 即可。
2.2.3. 计算变量
功能:根据现有变量和公式计算出一个新的变量。
菜单路径:转换 → 计算变量
操作步骤:打开 计算变量 对话框(图 1.2),按以下方式设置:
例1.4 计算人均gdp,命名为
gdp_per_capita
其中人均gdp的计算公式为:\[人均gdp=gdp/人口数\qquad{(2.1)}\]
具体的,计算过程如下:
目标变量:
gdp_per_capita点 类型与标签,打开 计算变量:类型和标签 对话框
- 标签: 人均gdp
- 类型:选择 数值
- 点 继续
数字表达式:
gdp/pop在上面的表达式中,gdp与pop可以手动输入,也可以通过双击 变量源列表 中对应的变量名输入
点 粘贴 获取语法代码
语法代码 2.4: 计算变量
COMPUTE gdp_per_capita=gdp / pop.
VARIABLE LABELS gdp_per_capita '人均gdp'.
EXECUTE.上面的语法代码块 2.4中,第1行是计算变量自己的语法,COMPUTE加上表达式,表达式等号左边是变量名,右边是表达式自身eq. 2.1;
第2行是设置变量标签的语法。会出现这一语法是由于我们在第二步设置了
类型与标签 第3行的 EXECUTE. 表示执行代码
运行上述代码后,可以在数据编辑器中看到出现了新的变量:
gdp_per_capita
2.2.4. 重编码
功能:将一个变量的旧值按照规则转换为新值,生成一个新变量。
两种常见用途:
- 字符变量 → 数值变量:字符串(如 "Asia")不能直接用于统计分析,必须转为数值编码(如 1)。
- 连续变量 → 等级变量:如将年龄划分为 "青年/中年/老年"(详见第3章频数表)。
本节重点:第一种情况(字符 → 数值)。SPSS提供两种方法:
- 手动重编码(转换 → 重新编码为不同变量):可精确控制每个旧值对应的新值。
- 自动重编码(转换 → 自动重新编码):由软件自动分配数值,省时但顺序不可控。
示例:在 gapminder.sav 中,将 continent 重新编码为新变量 continent_coded,规则为 Asia: 1, Europe: 2, Africa: 3, Americas: 4, Oceania: 5。
2.2.4.1. 利用 重新编码为其他变量 功能
菜单路径:转换 → 重新编码为不同变量
操作步骤:
- 打开 重新编码为其他变量 对话框(图 2.10)。
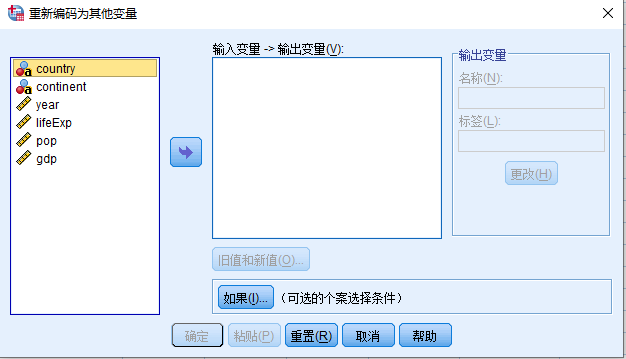
变量源列表 (continent) > 输入变量 -> 输出变量
输出变量
- 名称:输入新变量名称
continent_coded - 标签:大洲
- 点击 更改
- 名称:输入新变量名称
点击 旧值和新值,打开 重新编码到其他变量:旧值和新值 对话框,如下图:
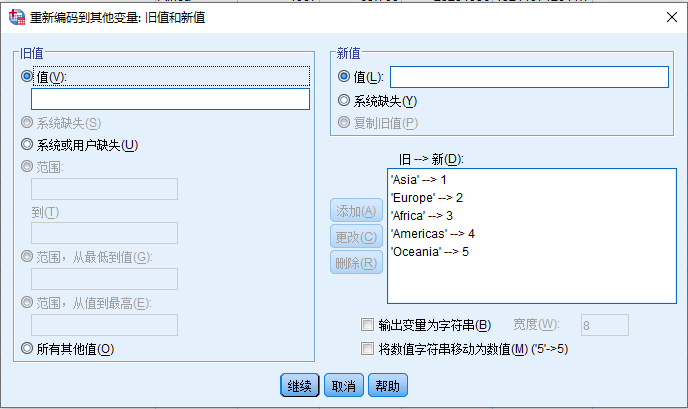
在本例中,旧值和新值是一一对应的关系,如果一个范围内的旧值编码成同一个新值的话(例如在频数表的编制过程中)需要选择范围相关的选项
- 在旧值和新值对话框中 图 2.11
,依次对各个旧值-新值配对按照下面的方式操作(下面以Asia编码为1为例):
- 旧值
- 值: Asia
- 新值
- 值: 1
- 点击 添加(A)
- 旧值
- 完成5对新旧值配对的定义后,点 继续 按钮回到 重新编码为其他变量 对话框 图 2.10
- 点 粘贴 获取语法代码
语法代码 2.5: 重编码为其他变量
RECODE continent ('Asia'=1) ('Europe'=2) ('Africa'=3) ('Americas'=4) ('Oceania'=5) INTO
continent_coded.
VARIABLE LABELS continent_coded '大洲'.
EXECUTE.在上面的语法代码 代码块 2.5 中:
RECODE ... INTO ...表示重编码,continent是原始变量('Asia'=1) ('Europe'=2) ...等多个括号里是旧值=新值的配对INTO后面的continent_coded是新变量的名称。
VARIABLE LABELS语句后面先后列出新变量的变量名和变量标签,为新变量定义标签。
2.2.4.2. 利用 自动重新编码 功能
适用场景:当只需要将字符串变量转为数值编码,且不关心各个类别对应的具体数字时,可使用此功能快速完成转换。
菜单路径:转换 → 自动重新编码
示例:将 continent 重新编码为新变量 continent_coded,5个大洲自动编码为1至5。
操作步骤:打开 自动重新编码 对话框(图 2.12),按以下方式设置:
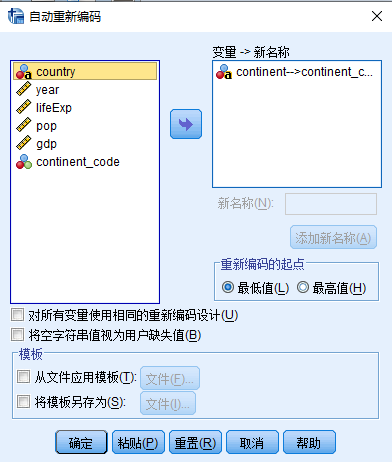
- 变量源列表 (continent) >
变量 -> 新名称 - 在
变量 -> 新名称中选择需要编码的变量 continent->??? - 新名称:输入新变量名: continent_coded
- 点击 添加新名称 按钮
- 重新编码的起点 列表
- 继续选择 最低值
注1:如果需要对多个变量重编码,而且重编码的规则是一致的,请注意勾选 [ ] 对所有变量使用相同的重新编码设计
注2:字符串变量的缺失值往往会被SPSS识别为空的字符串:
"", 所以除非空值代表特定意义,一般建议勾选 [ ] 将空字符串值视为用户缺失值
生成代码如下:
语法代码 2.6: 自动重编码
DATASET ACTIVATE 数据集1.
AUTORECODE VARIABLES=continent
/INTO continent_coded
/GROUP
/BLANK=MISSING
/PRINT.在变量视图里可以看到新生成的变量不仅将原先的字符串转换成了
名义 类型变量,还很贴心的根据原先的字符串内容设置好了
值标签,唯一美中不足的地方就是没有一并设置好
变量标签, 只要在 代码块 2.6 后面参考 代码块 2.5 多加一句
VARIABLE LABELS continent_coded '大洲'.
就可以解决这一问题。
可以看到如果对于字符串中各种值的先后排列顺序没有特定的要求,自动重新编码功能也是非常好用的选择
2.2.5. 筛选
功能:按照指定条件选取一部分记录,后续分析只针对选中的记录进行。
菜单路径:数据 → 选择个案
示例:从 gapminder.sav 中筛选出年份等于2007的记录,以便统计该年各大洲人口的平均值。
操作步骤:
- 打开 选择个案 对话框(图 2.13)。
- 选择
- 如果条件满足 点击 如果(I) 按钮 打开 条件定义 对话框
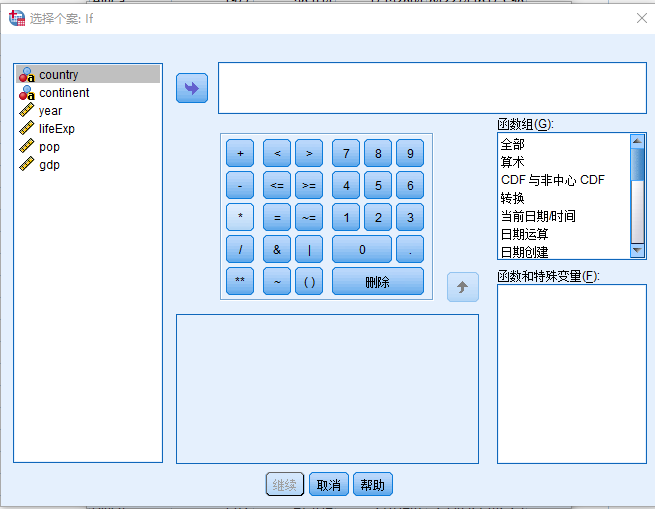
Figure 2.13: 条件定义 - 在 图 2.13
对话框中录入筛选表达式
- 变量源列表:双击
year - 补全表达式:year=2007 点 继续 回到 选择个案 对话框
- 变量源列表:双击
- 输出
- 选择 过滤掉未选定的个案
- 点 粘贴 生成如下语法代码:
语法代码 2.7: 过滤记录
USE ALL.
COMPUTE filter_$=(year=2007).
VARIABLE LABELS filter_$ 'year=2007 (FILTER)'.
VALUE LABELS filter_$ 0 'Not Selected' 1 'Selected'.
FORMATS filter_$ (f1.0).
FILTER BY filter_$.
EXECUTE.代码 代码块 2.7 说明: -
USE ALL. 表示使用所有数据,相当于清空之前已经存在的筛选 -
正如界面与 计算变量 非常类似,生成的语法也与之相同:
COMPUTE filter_$=(year=2007).是通过逻辑判定
year 变量值是否等于2007,等于的会得到值
1,而不等于的会得到值 0 - 接下来的
VARIABLE LABELS 是给新生成的计算变量 filter_$
设置变量标签 - 第4行的 VALUE LABELS
是新出现的语句,这个语句负责设置变量值的标签,在 #2.6
会再进一步讨论 - 第5行是设置数字格式 - 第6行则是表明使用新生成的变量
filter_$ 作为筛选变量
运行这些代码以后,可以看到年份不等于2007的记录前面的 行标签 会被打上斜线,表示这些记录不会进入后续的分析。
2.2.6. 再谈一下值标签
功能:为变量的各个取值设置文字说明,方便结果解读。
两种设置方式:
- 图形界面:在变量视图中点击变量的 值 单元格,逐个添加(见 2.1.2.1)。
- 语法命令:使用
VALUE LABELS语句批量设置,适合需要重复操作或保留操作记录的场景。
在 小节 2.2.5 (筛选) 生成的 代码块 2.7 里,已经出现了设置值标签的语句,其通用格式如下:
语法代码 2.8: 设置值标签的语法代码
VALUE LABELS 设置值标签的变量名 变量值#1 '值标签#1' 变量值#2 '值标签#2'.依照上面的格式,我们可以手动编写语法实现设置值标签的工作。
例1.7 之前在 小节 2.2.4.1 (利用 重新编码为其他变量
功能) 我们通过重编码新建了变量 continent_coded
,接下来请参照 代码块 2.8
的语法设置这个变量的值标签:1:亚洲,2:欧洲,3:非洲,4:美洲,5:大洋洲
语法代码 2.9: 设置值标签的语法代码-2
VALUE LABELS continent_coded
1 '亚洲 '
2 '欧洲 '
3 '非洲'
4 '美洲'
5 '大洋洲'.
EXECUTE.运行代码后可自行到变量视图的 continent_coded
变量中检查值标签是否被设置好了。
需要注意:
- 上面的代码中,一个值和它对应的标签之间可以独占一行,这样方便编写和阅读
- 注意值和其标签之间有一个空格
- 所有的标点符号都是英文符号,比如
'不是‘,"不是“,.不是。 VALUE LABELS语句结束后如果没有其他要做的步骤,应该跟上一个EXECUTE.来执行代码- SPSS会给语法代码添加高亮显示,也就是说如果你的代码中语法词应该是蓝色的,比如像下面这样:

请注意
行号 46对应的EXECUTE.没有显示成蓝色,这是因为行号 45的VALUE LABELS语句组最后结束的时候没有加.。所以如果发现语法高亮出现问题以后,请先检查一下代码里面有没有这种低级错误。
2.3节. 习题
打开 c1_exe_01.sav 文件,完成以下练习:
- 参考 小节 2.1.2 (变量视图)
设置变量标签:
- gender:性别
- age:年龄
- height:身高
- weight:体重
- 将gender变量按照
男性:1,女性:2的规则重编码,请注意:该变量对性别包含多种描述,包括male,man,female等,对其重编码首先需要知道gender变量包含哪些具体的值,然后利用重编码将各种值进行编码。重编码后的新变量名称请命名为gender_code,标签为性别。- 使用 分析>描述性统计>频率 工具绘制gender的频数表,这样就可以知道该变量具体包含哪些值
- 参考 小节 2.2.4.1 (利用 重新编码为其他变量 功能) 使用重编码为不同的变量功能进行重编码
- 参考 小节 2.1.2.1
(设置值标签的方法) 以及 小节 2.2.6 (再谈一下值标签)
按照
男性:1,女性:2的方式对gender_code设置值标签
- 按照\(bmi=\frac{weight}{height^2}\)的公式,参考 小节 2.2.3 (计算变量) 使用计算变量工具生成bmi变量
- 参考 小节 2.2.2 (拆分)
依据性别分组,统计各组
bmi变量的算数平均值。算数平均值的计算方法可以参考第二章中[#2.4.1 使用频率对话框计算] - 参考 小节 2.2.1 (排序) 将数据优先按照年龄升序排列,次要按照身高降序排列
- 按照原文件名保存数据文件
习题技能对照与快速查阅
题号 考察技能 对应讲义小节 第1题 设置变量标签 2.1.2 变量视图 第2题 查看变量的取值分布(频数表) 第3章 描述性统计(频率工具) 将字符串变量重编码为数值变量 2.2.4.1 重新编码为其他变量 为编码后的变量设置值标签 2.1.2.1 设置值标签的方法、2.2.6 再谈一下值标签 第3题 根据公式计算新变量 2.2.3 计算变量 第4题 按分组变量拆分文件,分组统计 2.2.2 拆分 第5题 按多个变量排序(升序/降序) 2.2.1 排序 第6题 保存为SPSS数据文件 2.1.4 数据存储