第4章. 统计表与统计图
4.1节. 统计表的制作
在绘制统计图的工作流程里,SPSS主要负责数据的整理和统计量的计算,而最后的制表主要是在文字处理软件中实现。如果你当前的系统里没有可用的文字编辑软件,可以使用在线文档(如腾讯文档)或者下载免费的WPS软件。除了此处的文字介绍,还可以参考本节讲解视频协助学习。
统计表的操作主要包括两块:
- 描述性统计量的计算
- 数据预处理(包括变量标签、值标签的设置,缺失值的处理,根据具体需要可能还要做文件拆分),这里可以参考 小节 2.2 (数据处理)
- 对于定量数据可以优先使用 探索 功能( 小节 3.4.2 (使用探索对话框计算) ),而分类数据则往往需要 频率 功能,以及 交叉表 功能。分类数据的统计量计算请参考相应章节【x】
- 在文字编辑软件中制作三线表
- 建立表格
- 录入数据
- 设置三线表格式、文本对齐以及文本字体字号。
第一部分在第二章中已经做过讲解,第二部分则主要是文字编辑软件中通过设置表格格式实现。具体通过本视频讲解
例3.1 打开bmi.sav文件,绘制表格比较不同bmi水平(<20,20~24,24~26,26~28,>28),各性别样本的样本量、患有冠心病人数(dis=1),以及患病率。
根据要求,该表格主标目是bmi所属的分组,而副标目则是性别,而第三层的标目则是样本量、患病人数以及患病率这三个变量。具体绘制过程可参考视频,此处不再赘述。其中
交叉表 功能会在第六章 卡方检验作具体讲解。
4.2节. 统计图的绘制
在 小节 3.2 (直方图) 和 小节 3.3 (正态性检验) 两节中我们已经接触了直方图、箱式图、QQ图等多种图形的绘制方式。在之前的讲义中,这些图形实际上是描述性统计工作流程中的副产品。在本节我们会从绘制图形的角度看一下一般的统计图绘制流程是怎样的。
4.2.1. 直方图
除了在 小节 3.2 (直方图) 中提到的,通过 频率 与 探索 两个对话框的绘制方式,我们也可以使用专门的直方图绘制对话框。
4.2.1.1. 常规直方图
菜单选择方式:
- 图形
- 旧对话框
- 直方图 打开 直方图 对话框
- 旧对话框
例3.2-1 打开bmi.sav, 绘制bmi(体重指数)的直方图
打开直方图对话框 图 4.1 后:
- 变量源列表 (bmi) >> 变量
- 如果需要一并显示正态曲线可以:
- 显示正态曲线
点击 粘贴 生成语法代码:
GRAPH
/HISTOGRAM(NORMAL)=bmi.思考题:如果要比较有无冠心病以及不同性别的样本的bmi直方图,可以如何绘制?提示:这时相当于用有无冠心病和性别将数据划分成2x2的四个格子,可以将两个变量分别纳入面板依据的行以及列
4.2.1.2. 人口金字塔
在流调中往往需要绘制人口金字塔,也就是两个呈镜像对称摆放的直方图。人口金字塔可以更好的对两个直方图进行相互的比较。
例3.2-2 继续使用上一题的数据:bmi.sav,绘制男女两性bmi的人口金字塔图
菜单选择方法:
- 图形
- 旧对话框
- 人口金字塔 打开 人口金字塔 对话框
- 旧对话框
- 计数
- 选择 从数据计算计数
- 变量源列表 (bmi) >> 显示分布
- 变量源列表 (gender) >> 分割依据
点击 粘贴 生成代码
XGRAPH CHART=[HISTOBAR] BY bmi[s] BY gender[c]
/COORDINATE SPLIT=YES
/BIN START=AUTO SIZE=AUTO
/DISTRIBUTION TYPE=NORMAL.将 绘制男女两性bmi的图形 这个需求中,变量关系是:性别 x bmi。bmi作为定量变量是直接向直方图提供x轴标目的,直方图的y标目来自统计计算所得的各区间频数,而性别则作为第三个标目实现左右分割的功能。在 小节 4.2.1.1 (常规直方图) 最后思考题所提到的可以利用行和列划分面板不同,人口金字塔会为了便于在二分变量的两类之间(比如此处的男女之间)更好的进行对比,将左右两个直方图的横轴进行严格对齐,并作纵轴的上下翻转,之后还有一个转置的变换,最终形成金字塔图的形态。
4.2.2. 箱式图
4.2.2.1. 分类变量 x 定量变量 的箱式图
例3.3 继续使用之前的数据bmi.sav,绘制箱式图,对比男性与女性人群的bmi
本例中,性别为自变量,bmi为因变量。
除了可以使用人口金字塔进行两性之间定量变量分布规律的比较,还可以使用箱式图这个工具。与人口金字塔只能处理 2分变量 x 定量变量 这种形式的问题不同,箱式图更为灵活多变。之前在 小节 3.3 (正态性检验) 中,我们已经利用探索工具生成过箱式图。但如果图形绘制的需求变得更复杂,还是要使用本节介绍的绘图工具。
菜单选择方法:
- 图形
- 旧对话框
- 箱图 打开 箱图 对话框: 图 4.2
- 旧对话框
- 选择 简单 类型
- 图表中的数据为:
- 选择 个案组摘要
- 点击 定义 打开 图 4.3
在上图的对话框中:
- 变量源列表 (bmi) >> 变量
- 变量源列表 (gender) >> 类别轴
- 点击 粘贴 按钮,生成代码如下:
语法代码 4.1: 简单箱式图的绘制语法
EXAMINE VARIABLES=bmi BY gender
/PLOT=BOXPLOT
/STATISTICS=NONE
/NOTOTAL.这里特别讲两点:
- 其实上面的语法和 小节 3.2.2
(利用探索对话框绘制) 中 代码块 3.4
用到的语法基本是一样的,都用到了
EXAMINE命令。 - 本例题属于分类变量 x 定量变量的形式,因此在 图 4.3
中就应该按照变量之间的关系,把定量变量
bmi交给变量一栏,而分类变量gender交给类别轴
4.2.2.2. 变量关系为 分类变量 x 分类变量 x 定量变量 类型的箱式图
当考虑的问题更为复杂一些以后,分类变量可能不止一个,比如下面的例题:
例3.4 继续使用之前的数据,绘制箱式图,分别在男性与女性人群中对比是否患有冠心病样本的bmi
根据题目要求,要对样本按照1.
是否具有冠心病和2.
性别进行分组,之后以bmi这个定量变量绘制箱式图。此处的dis和gender都是自变量,而bmi则是因变量。若要在两个自变量之间进一步仔细划分的话,dis是该项研究中更直接关心的自变量,性别gender应该归类为协变量。
故本例需要直接比较是否患有冠心病两类样本的bmi值,性别则是作为套在是否患有冠心病外层的分组变量,如果要写成变量关系的话应该是:
gender x dis x bmi。因为分类变量超过了1个,现在需要绘制复式箱式图
菜单选择方式:
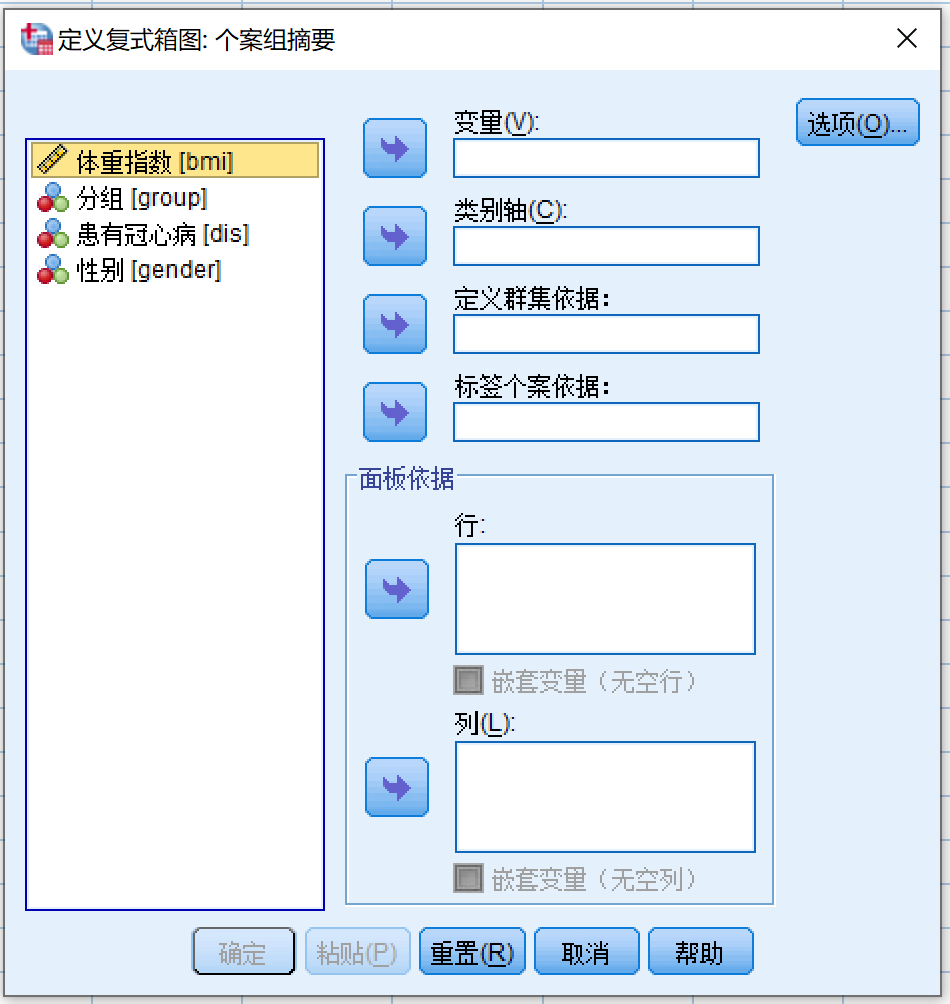
与简单箱式图的个案组摘要 图 4.3 相比,现在的对话框增加了 定义群集依据,在这一对话框中:
- 变量源列表 (bmi) >> 变量
- 变量源列表 (gender) >> 类别轴
- 变量源列表 (dis) >> 定义群集依据
- 点击 粘贴 按钮,生成代码如下:
语法代码 4.2:
EXAMINE VARIABLES=bmi BY gender BY dis
/PLOT=BOXPLOT
/STATISTICS=NONE
/NOTOTAL.生成统计图如下所示
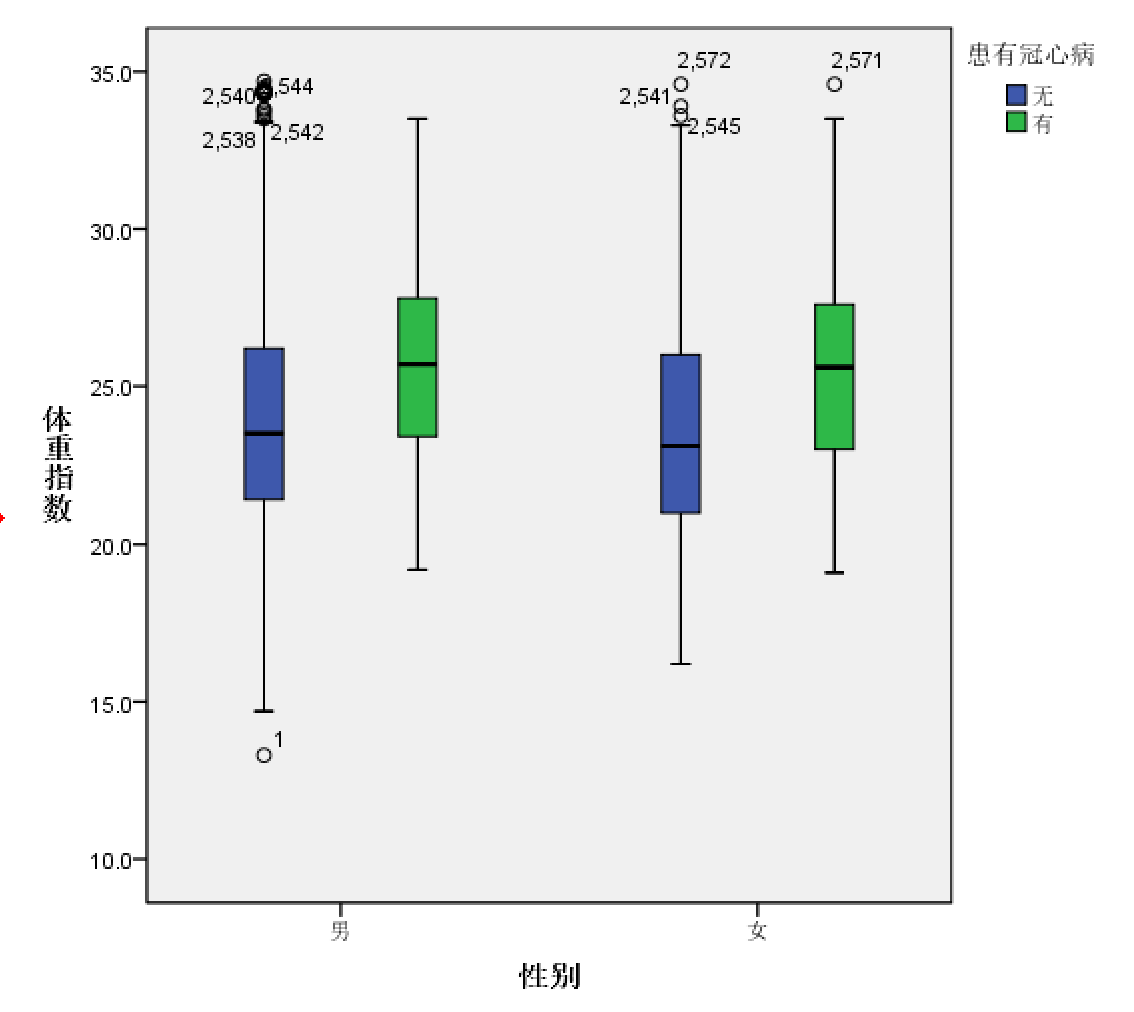
可以看到图形中纵轴是体重指数(bmi),横轴则是性别,包含两个值:男和女,而第三个标目则是是否患有冠心病(有/无)。如果与代码相对应:VARIABLES=bmi BY gender BY dis,语句中等号后面的第一个变量是纵轴表示的变量:bmi,BY后面跟着的gender则是横轴(第二标目):性别,而dis排在最后,是第三标目,在图中以图例的形式展现。通过这种方式组织变量顺序可以让同一性别组内有无冠心病的箱式图相互比邻。那么,如果现在问题改成分别在有无冠心病人群中比较男性和女性bmi值,那么又应该如何在
图 4.4
中设置类别轴和定义群集依据呢?
在刚才两个例子中,图表中的数据 选项我们都选择了 个案组摘要,接下来我们看另外一个例子。
4.2.2.3. 宽数据形式下的箱式图绘制
例3.5 打开dbp.sav,该数据集收集了20例受试者三个时间点的舒张压数据,分别是基线舒张压(DBPBL),运动测试30分钟后的舒张压(DBPat30min)以及60分钟后的舒张压(DBPat60min)。现在尝试绘制这三个时间点所有样本舒张压的箱式图
本例中三个时间点为自变量,舒张压的数值为因变量。
如果将dbp.sav与前面使用的bmi.sav数据集相比较,可以看到本例使用的数据集相对比较的宽,而bmi.sav数据集则相对比较长。作为与之相对比的例子,可以打开dbp_long.sav看一下如果将该数据集转换成比较长的形式,是长成什么样子的。
思考题:如果现在使用的是
dbp_long.sav数据集,需要绘制三个时间点的舒张压箱式图,应该如何操作?提示:参考 小节 4.2.2.1 (分类变量 x 定量变量 的箱式图)
对于宽数据,同一个变量(如例子中的舒张压)在不同类别下(如例子中的时间点:基线,30分钟和60分钟)的值由不同的变量展示。宽数据和长数据两种形式并无孰优孰劣,因此SPSS对于两种形式都提供了绘制统计图的工具。回到本例:
菜单操作方式:
- 图形
- 旧对话框
- 箱图 打开 箱图 对话框 图 4.2
- 旧对话框
- 选择 简单 类型
- 图表中的数据为:
- 选择 各个变量的摘要
- 点击 定义
对话框如下图所示: 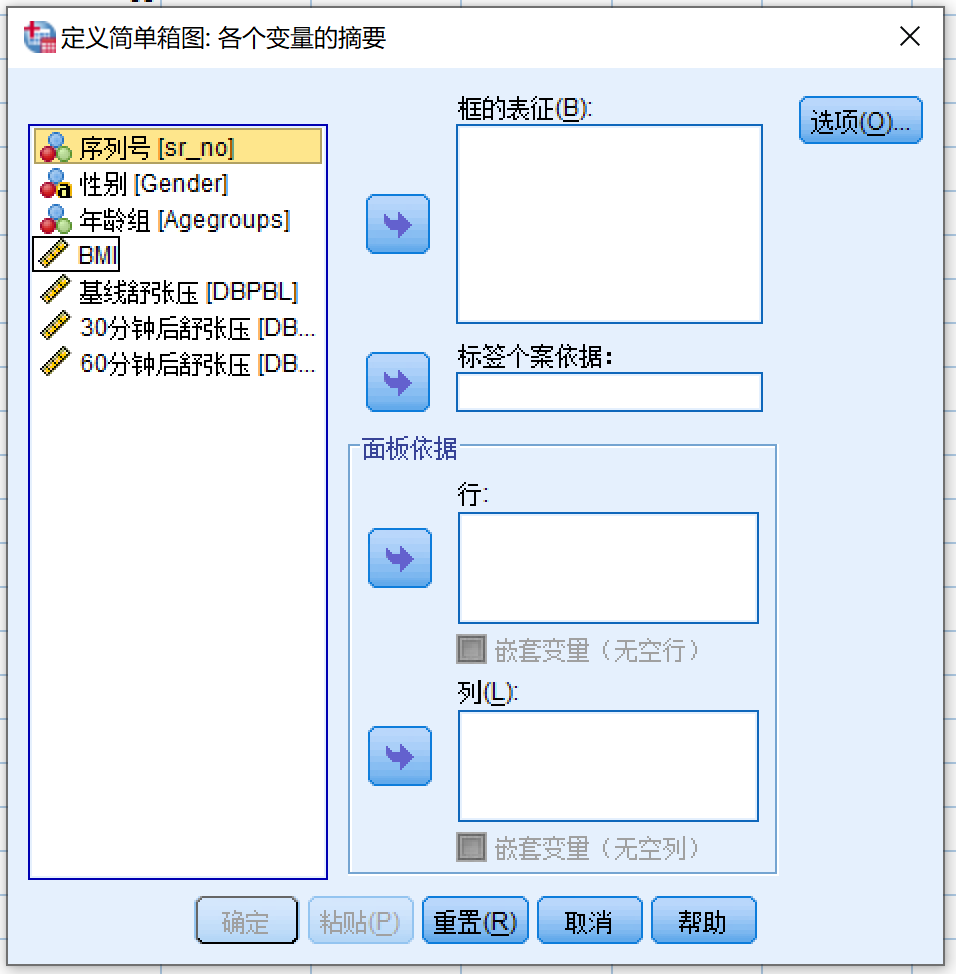
如前所述,宽数据是将一个变量在各组的情况用多个变量展示,所以现在需要把所有相关的变量纳入 框的表征
- 变量源列表 (DBPBL) >> 框的表征
- 变量源列表 (DBPat30min) >> 框的表征
- 变量源列表 (DBPat30min) >> 框的表征
点击粘贴按钮生成代码:
EXAMINE VARIABLES=DBPBL DBPat30min DBPat60min
/COMPARE VARIABLE
/PLOT=BOXPLOT
/STATISTICS=NONE
/NOTOTAL
/MISSING=LISTWISE.不妨将 代码块 4.1 的代码放在下面相互对比一下:
EXAMINE VARIABLES=bmi BY gender
/PLOT=BOXPLOT
/STATISTICS=NONE
/NOTOTAL.本例的/COMPARE VARIABLE如果删除,生成的统计图会变成什么样,各位读者可以自行尝试一下。
4.2.2.4. 宽数据向长数据的转化
虽然前面说了长数据和宽数据并没有孰优孰劣,但是毫无疑问长数据形式适于应对复杂多变的情况。所以,将宽数据转换成长数据是很重要的技能。
例3.6 将 dbp.sav
中宽数据类型的DBPBL,DBPat30min和DBPat60min三个变量转换成长数据形式。即:三个变量转换成两个变量:测量时间(timepoint)和舒张压(dbp)
下图展示了宽数据向长数据的转换的过程:
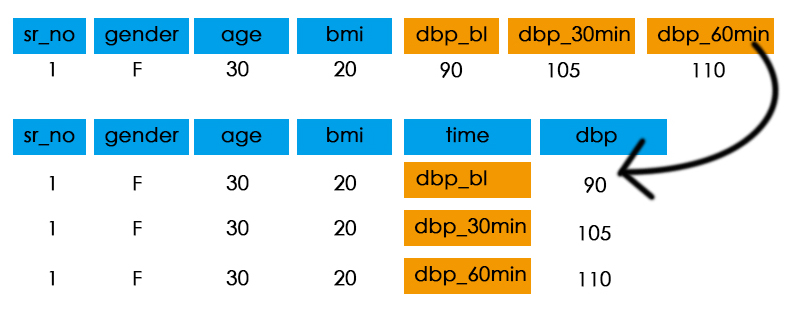
上图以dpi.sav的一条记录为例,该记录共有7个变量,其中sr_no,
gender, age,
bmi四个变量不需要作转换,而dbp_bl,dbp_30min和dbp_60min三个变量需要作转换,从三个值(90, 105, 110)并列一行变成并列一列。
但是单纯将三个值旋转成并列一列会出现两个问题:
- 原先一行的数据现在变成了三行,那么第二行和第三行的
sr_no,gender,age,bmi四个变量的值会变成空缺值 - 如果只用一个变量记录
90, 105, 110三个值,我们没办法区分到底哪个是在基线,哪个是30分钟以及哪个是60分钟。因为测量时间点的信息之前是保存在三个变量的变量名里面的。
对于第一个问题,我们可以简单的将四个变量第一行的内容向第二行和第三行填充。可以接受这种处理的变量,SPSS中称其为固定变量
而对于第二个问题,可以看到单纯只用一列去记录原来并排一行的三个值是不够的(SPSS中称其为目标变量),我们还需要额外的一列去记录三个值各自表示的意义(SPSS中称其为索引变量)。讲解完其中的原理以后,我们看一下具体的操作。
菜单操作方式:
- 数据
- 重组 打开重组数据向导
- 您希望做什么?
- 选择将选定变量重组为个案
- 点击下一步
- 您希望重组多少个变量组?
- 选择一个(例如,w1,w2和w3)
- 点击下一步 进入下图所示界面 图 4.6
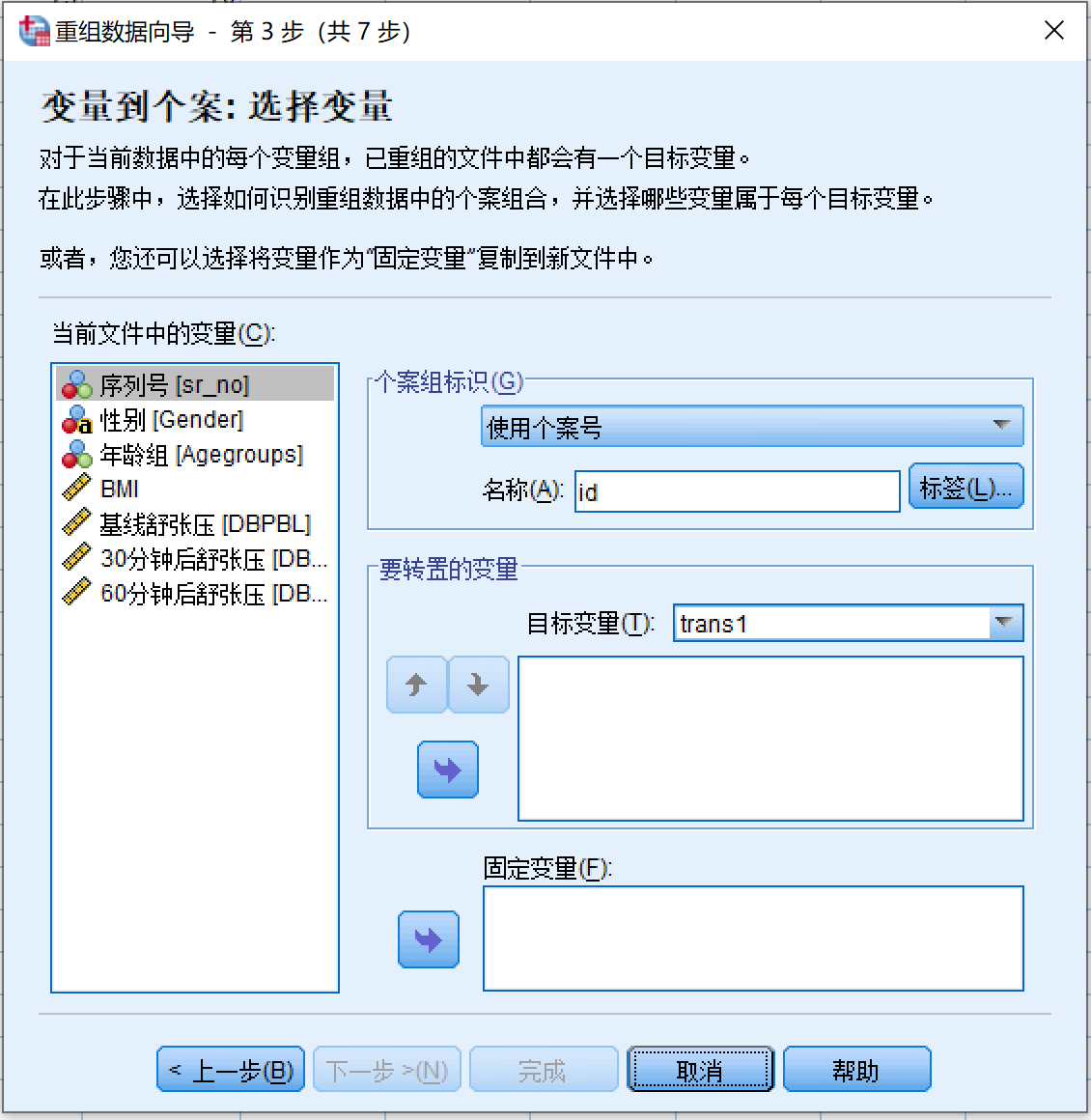
- 在第三步的界面 图 4.6 中
- 个案组标识:
- 一般可以选择使用个案号,但本例中
sr_no本身就是个案组标识,所以此处选择使用选定变量- 当前文件中的变量 (sr_no) > 变量
- 一般可以选择使用个案号,但本例中
- 要转置的变量
- 当前文件中的变量 (dbpbl) > 要转置的变量
- 当前文件中的变量 (dbpat30min) > 要转置的变量
- 当前文件中的变量 (dbpat60min) > 要转置的变量
- 目标变量:软件已自动命名为trans1,可以更改其他名称,如dbp
- 固定变量
- 当前文件中的变量 (gender) > 固定变量
- 当前文件中的变量 (agegroups) > 固定变量
- 当前文件中的变量 (bmi) > 固定变量
- 点击下一步
- 个案组标识:
- 第4步: 您希望创建多少索引变量?
- 选择一个
- 点击下一步
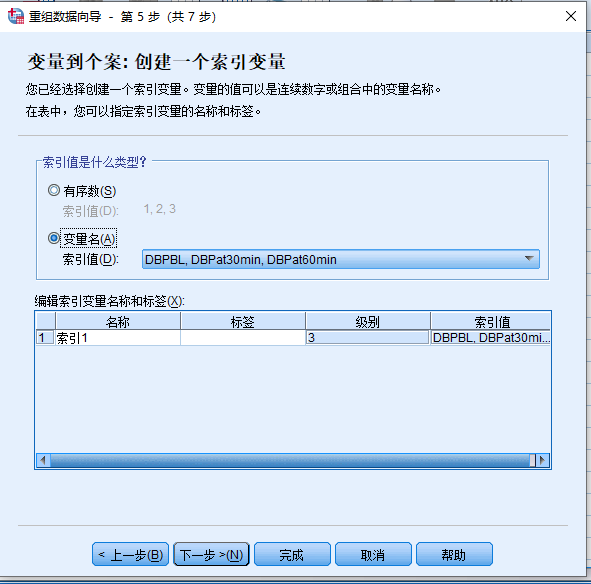
- 第5步:创建一个索引变量:
- 索引值是什么类型?
- 选择变量名。注:这里一般建议选择变量名,之后再对索引变量作重编码,这样操作比较稳妥
- 编辑索引变量名称和标签
- 名称:双击空白单元格后,输入索引变量名称,如
timepoint - 标签:双击空白单元格后,输入索引变量标签,如
测量时间点
- 名称:双击空白单元格后,输入索引变量名称,如
- 点击下一步
- 索引值是什么类型?
- 第6步:选项
- 保留默认选项,点击下一步
- 第7步:完成
- 选择将本向导生成的语句粘贴到语法窗口
- 点击完成
生成语法代码如下:
VARSTOCASES
/MAKE dbp FROM DBPBL DBPat30min DBPat60min
/INDEX=timepoint "测量时间"(dbp)
/KEEP=sr_no Gender Agegroups BMI
/NULL=KEEP.运行语法后,原数据集从宽数据转换成了长数据
4.2.3. 折线图
4.2.3.1. 折线图的绘制方式
对于 时间序列,常用的统计图是折线图。
时间序列(或称动态数列)是指将同一统计指标的数值按其发生的时间先后顺序排列而成的数列。所以时序数据至少包含两个变量:时间,以及随时间变化的变量。
例3.7 打开fb_google.sav数据集,该数据集是FACEBOOK与GOOGLE两个股票股价波动的情况。请绘制折线图比较两个股票股价波动情况。
本例中日期和股票名称为自变量,股价为因变量
股价是典型的时间序列,该数据集包括三个变量FB,GOOG和date。时序变量的折线图一般以时间作为横轴,股价放在纵轴
菜单操作方式:
- 图形
- 旧对话框
- 折线图
- 旧对话框
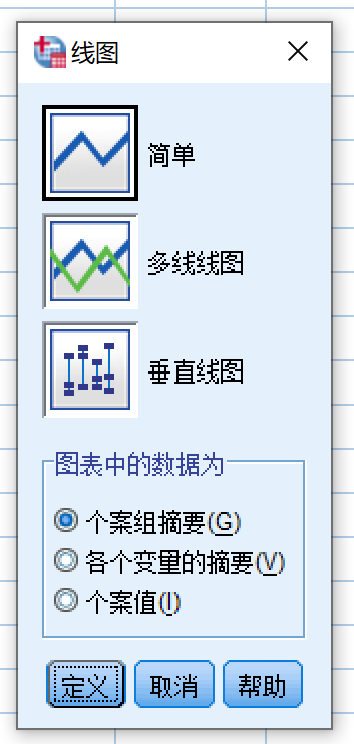
请注意,本数据属于宽数据类型(请思考:本数据集的长数据形式会是什么样子的?可以尝试参照 小节 4.2.2.4 (宽数据向长数据的转化) 的方式转换成长数据),应参考 小节 4.2.2.3 (宽数据形式下的箱式图绘制) 的形式操作:
- 选择 多线线图
- 图表中的数据为:
- 选择 各个变量的摘要 点击定义
打开下图所示对话框:
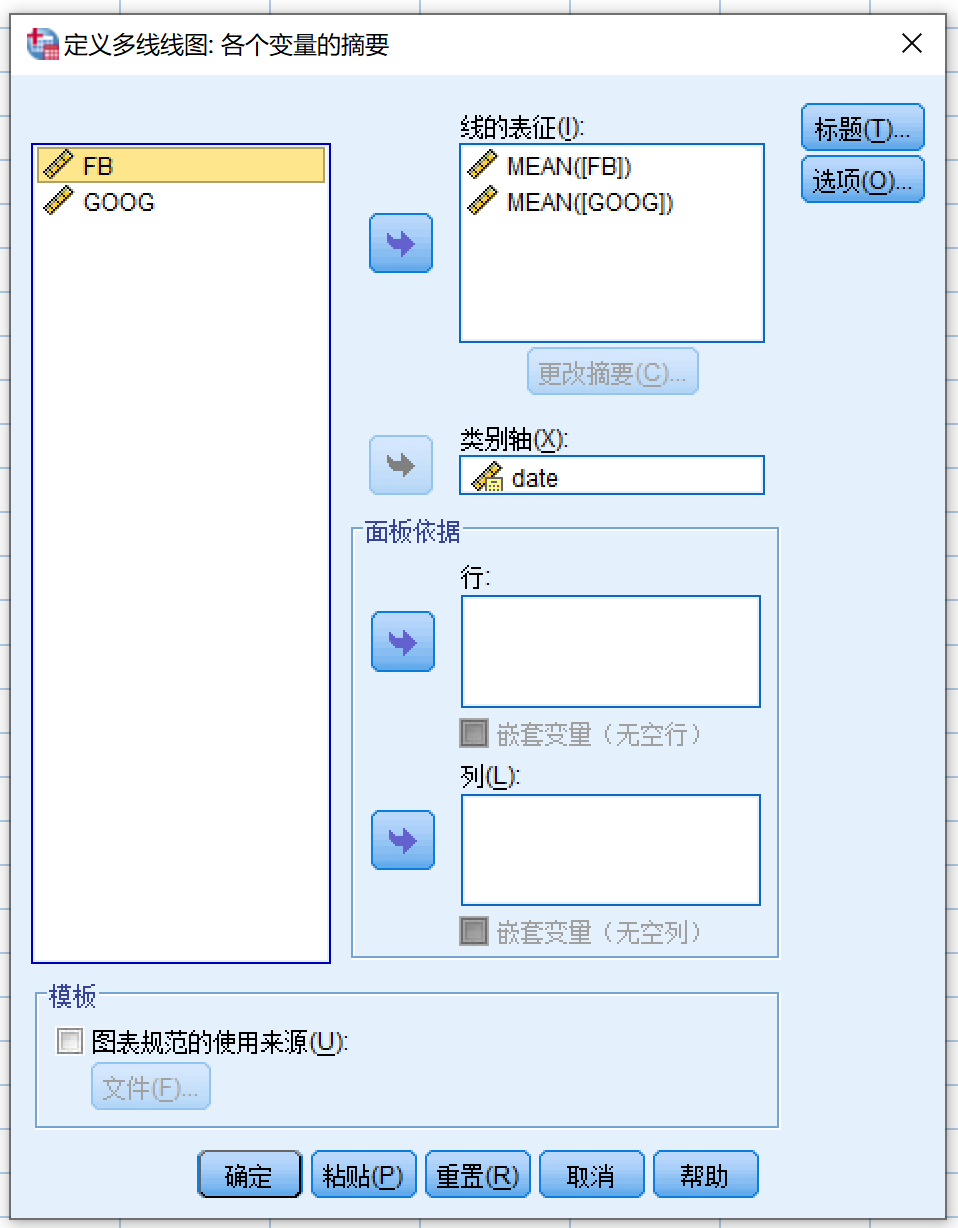
- 变量源列表 (FB) >> 线的表征
- 变量源列表 (GOOG) >> 线的表征
- 变量源列表 (date) >> 类别轴
点击粘贴生成代码:
GRAPH
/LINE(MULTIPLE)=MEAN(FB) MEAN(GOOG) BY date
/MISSING=LISTWISE.虽然在本例中一个特定时间点某只股票只有一个价格值,但SPSS中默认会计算统计量。当然,单一值的均值仍旧是该值,所以也没有太大问题。
4.2.3.2. 补充:纵轴的对数变换
生成统计图后,还可以对统计图做一些修正。比如可以对纵轴作对数变换:
- 在输出窗口双击统计图
- 在图表编辑器中,双击纵轴刻度,打开 属性 对话框
- 在 刻度 页:
- 类型:
- 选择对数
- 点击应用
- 类型:
4.2.4. 条形图
在箱式图一节中,我们学习了如何绘制普通箱式图 小节 4.2.2.1 (分类变量 x 定量变量 的箱式图) 和复式箱式图 小节 4.2.2.2 (变量关系为 分类变量 x 分类变量 x 定量变量 类型的箱式图) 。条形图也是重要的组间定量变量比较工具,与前者主要展示分位数不同,条形图主要展示的是均值和标准差这两个统计量。
4.2.4.1. 简单误差条形图: 分类变量 x 定量变量
例3.8 使用bmi.sav数据集,绘制条形图比较样本中男性与女性bmi的平均值,并加入误差条展示标准差(误差条单边长度为1倍标准差)
菜单操作方式:
- 图形
- 旧对话框
- 条形图
- 旧对话框
打开 条形图 对话框
在具体讲如何操作以前,我们先回顾一下前面几节( 小节 4.2.2.1 (分类变量 x 定量变量 的箱式图), 小节 4.2.2.2 (变量关系为 分类变量 x 分类变量 x 定量变量 类型的箱式图), 小节 4.2.2.3 (宽数据形式下的箱式图绘制))是如何选取合适的绘图选项的。首先我们要问自己以下的问题:
- 数据是 长数据 还是 宽数据?
- 长数据 则 图表中的数据为 选项一般选择 个案组摘要
- 宽数据 则 图表中的数据为 选项一般选择 各个变量的摘要
- 涉及标目数量有多少?
- 如果只需要处理两个变量,也就是
分类变量 x 定量变量形式的问题,那么大部分统计图都可以用横轴和纵轴接纳这两个变量,因此可以使用 简单… 类型的统计图 - 如果需要处理三个,甚至更多的变量,也就是
分类变量 x 分类变量 x 定量变量形式的问题,那么至少需要加入一个额外的标目,一般以 图例 的形式加入统计图。这个时候可以使用 复式… 类型的统计图
- 如果只需要处理两个变量,也就是
本例的问题是 分类变量 x 定量变量
形式的问题,所以上面两个问题的答案分别是什么?
- 统计图类型 选择 简单箱图
- 图表中的数据为 选择 个案组摘要
- 点击定义打开对话框
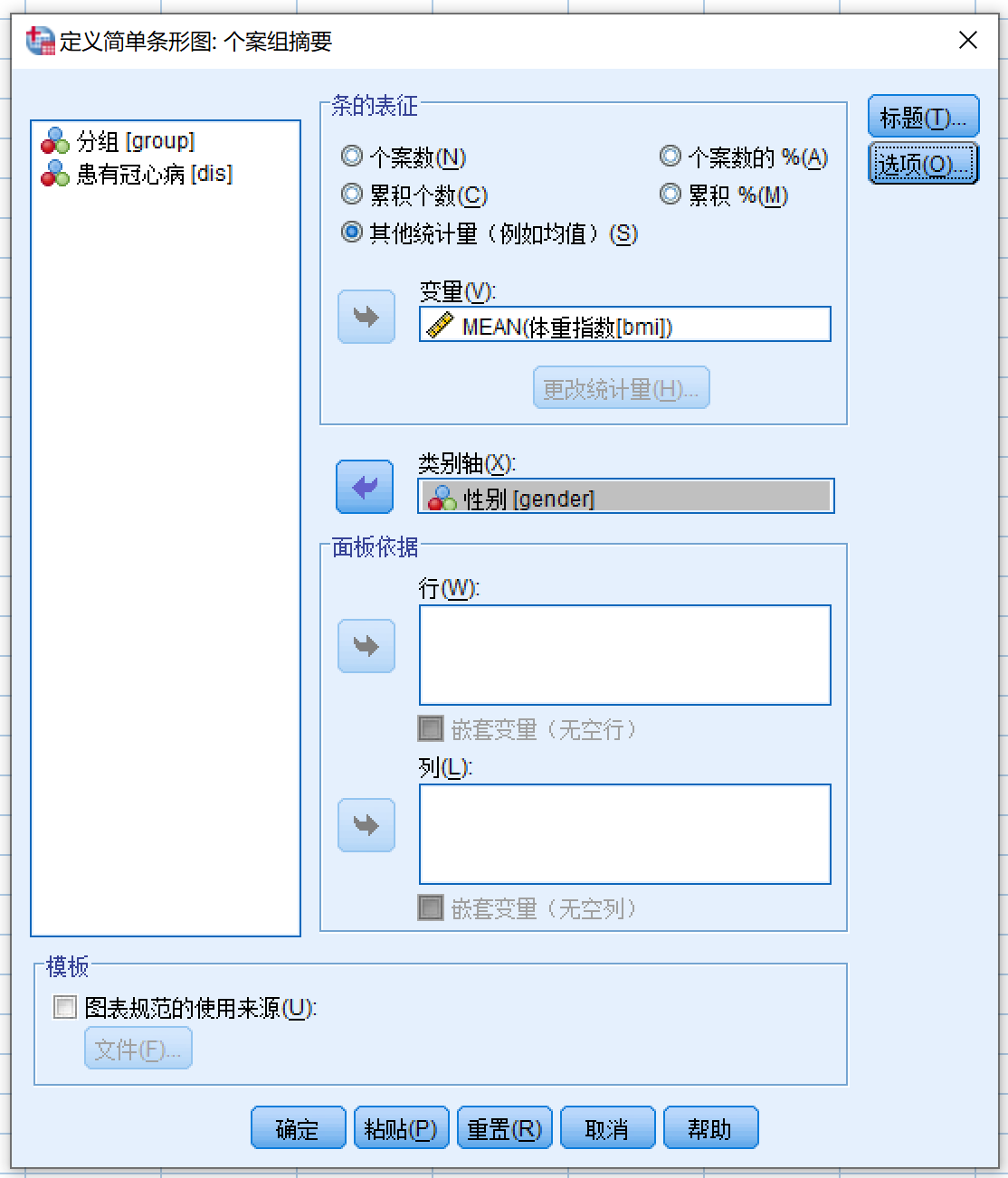
- 条的表征 根据例题要求选择 其他统计量(例如均值)
- 变量源列表 (bmi) > 变量
- 统计量默认使用均值,因此无需更改,不用点击更改统计量
- 变量源列表 (gender) > 类别轴
- 点击选项按钮,打开下图所示对话框
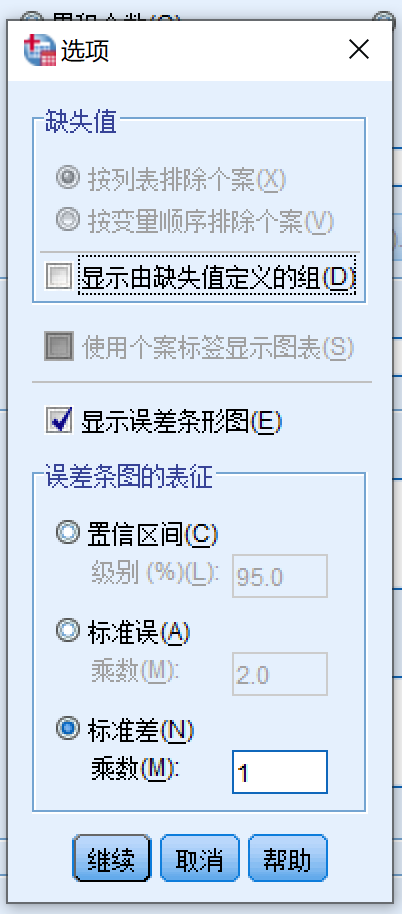
- 显示误差条形图
- 误差条图的表征 列表中
- 选择标准差
- 乘数:1
- 选择标准差
4.2.4.2. 复式条形图绘制 分类变量 x 分类变量 x 定量变量
在 小节 4.2.2.2 (变量关系为 分类变量 x 分类变量 x 定量变量 类型的箱式图) 中,我们绘制了箱式图比较了不同性别样本中,是否患有冠心病人员的bmi值。如果要绘制条形图,操作也是相似的。
例3.8-2 使用bmi.sav数据集,绘制条形图比较男性与女性人群中是否患有冠心病样本的bmi。(以条形图高度表示均值,误差条为1倍标准差)
本例的问题是 分类变量 x 分类变量 x 定量变量
的问题,且数据是长数据,因此在 图 4.8
中:
- 统计图类型 选择 复式条形图
- 图表中的数据为 选择 个案组摘要
- 点击定义打开对话框 图 4.11
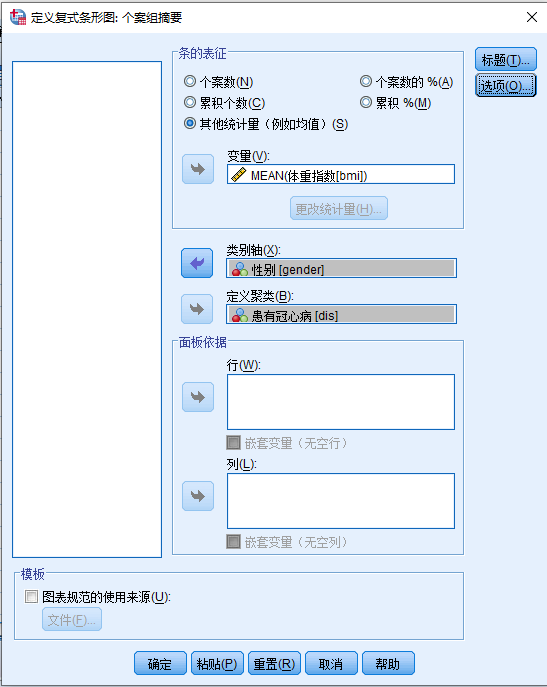
与 小节 4.2.2.2 (变量关系为 分类变量 x 分类变量 x 定量变量 类型的箱式图) 中的操作相类似的:
- 条的表征 根据例题要求选择 其他统计量(例如均值)
- 变量源列表 (bmi) > 变量
- 统计量默认使用均值,因此无需更改,不用点击更改统计量
- 变量源列表 (gender) > 类别轴
- 变量源列表 (dis) > 定义聚类
- 点击选项按钮,打开误差条定义对话框 图 4.10 ,参照前一节 小节 4.2.4.1 (简单误差条形图: 分类变量 x 定量变量) 的方式定义误差条为1倍标准差
最后生成语法如下
GRAPH
/BAR(GROUPED)=MEAN(bmi) BY gender BY dis
/INTERVAL SD(1).不妨将上面的语法代码与 小节 4.2.2.2 (变量关系为 分类变量 x 分类变量 x 定量变量 类型的箱式图) 中的代码 代码块 4.2 相对比,看看有何异同。
4.2.4.3. 宽数据的复式条形图绘制 分类变量 x 分类变量(以宽数据形式出现) x 定量变量
例3.9 打开数据dpi.sav,绘制误差条形图,分别比较男性与女性各个时间点的舒张压
数据属于宽数据,本题除了性别和舒张压两个变量以外,还额外要求加入时间点这一变量。故:
菜单操作方式:
- 图形
- 旧对话框
- 条形图
- 旧对话框
打开 条形图 对话框 图 4.8
根据本题情况,依次回答 小节 4.2.4.1
(简单误差条形图: 分类变量 x 定量变量)
中的几个问题:本例是宽数据,而且属于
分类变量 x 分类变量 x 定量变量 类型的问题,因此:
- 统计图类型 选择 复式条形图
- 图表中的数据为 选择 各个变量的摘要
- 点击定义打开对话框:
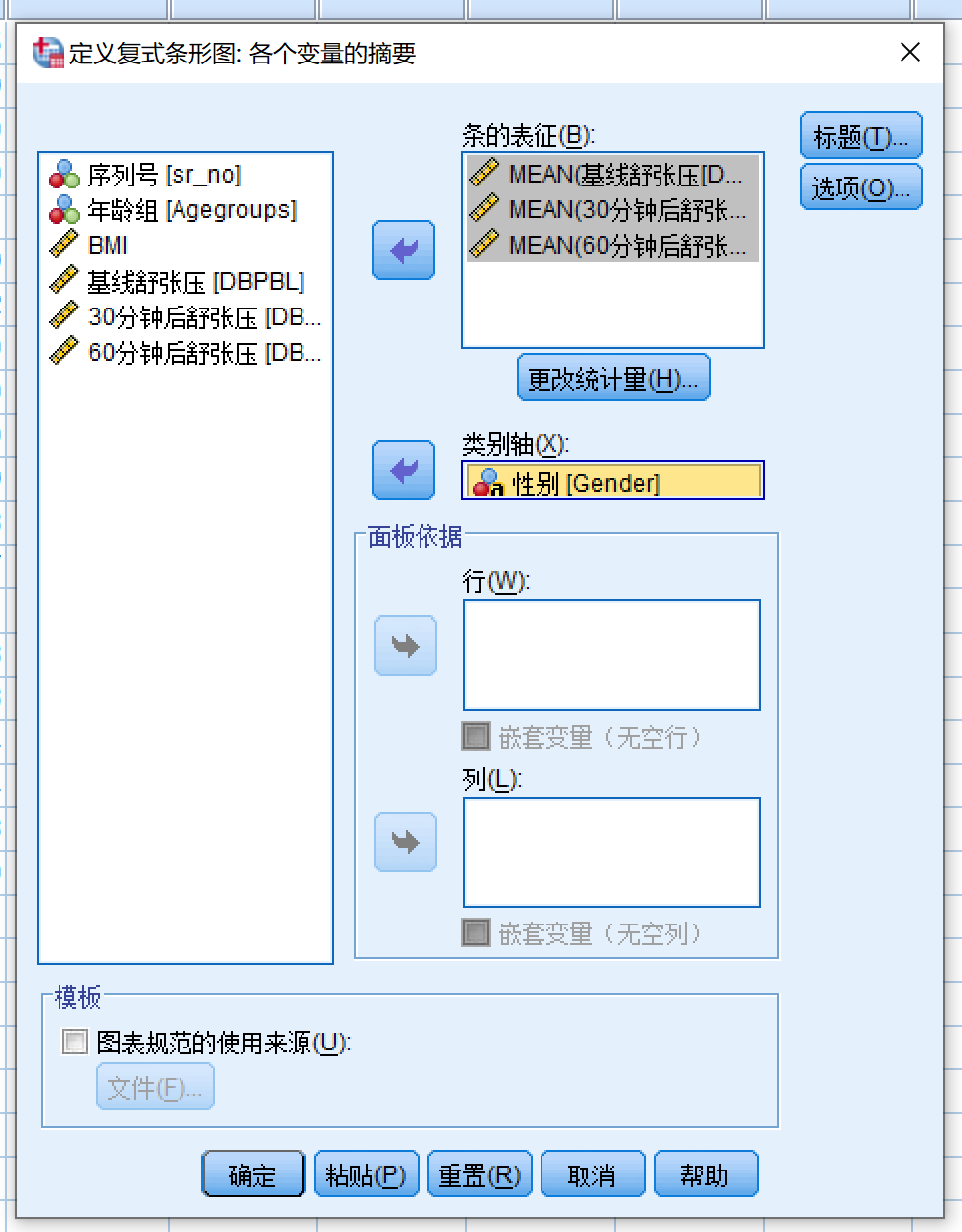
- 变量源列表 (DBPBL) >> 条的表征
- 变量源列表 (DBPat30min) >> 条的表征
- 变量源列表 (DBPat60min) >> 条的表征
- 变量源列表 (gender) >> 类别轴
- 点击选项按钮,参考前例 小节 4.2.4.1 (简单误差条形图: 分类变量 x 定量变量) 设置误差条
生成语法代码如下:
GRAPH
/BAR(GROUPED)=MEAN(DBPBL) MEAN(DBPat30min) MEAN(DBPat60min) BY Gender
/MISSING=LISTWISE
/INTERVAL SD(1).4.2.4.4. 宽数据的复式条形图绘制问题的变体:分类变量(以宽数据形式出现) x 分类变量 x 定量变量
例3.10 打开数据dpi.sav,绘制误差条形图,分别比较不同时间点下,男性与女性舒张压的水平
本例与前例的区别在于横轴标目(类别轴)与图例标目互换了。绘制的统计图应如下图所示:
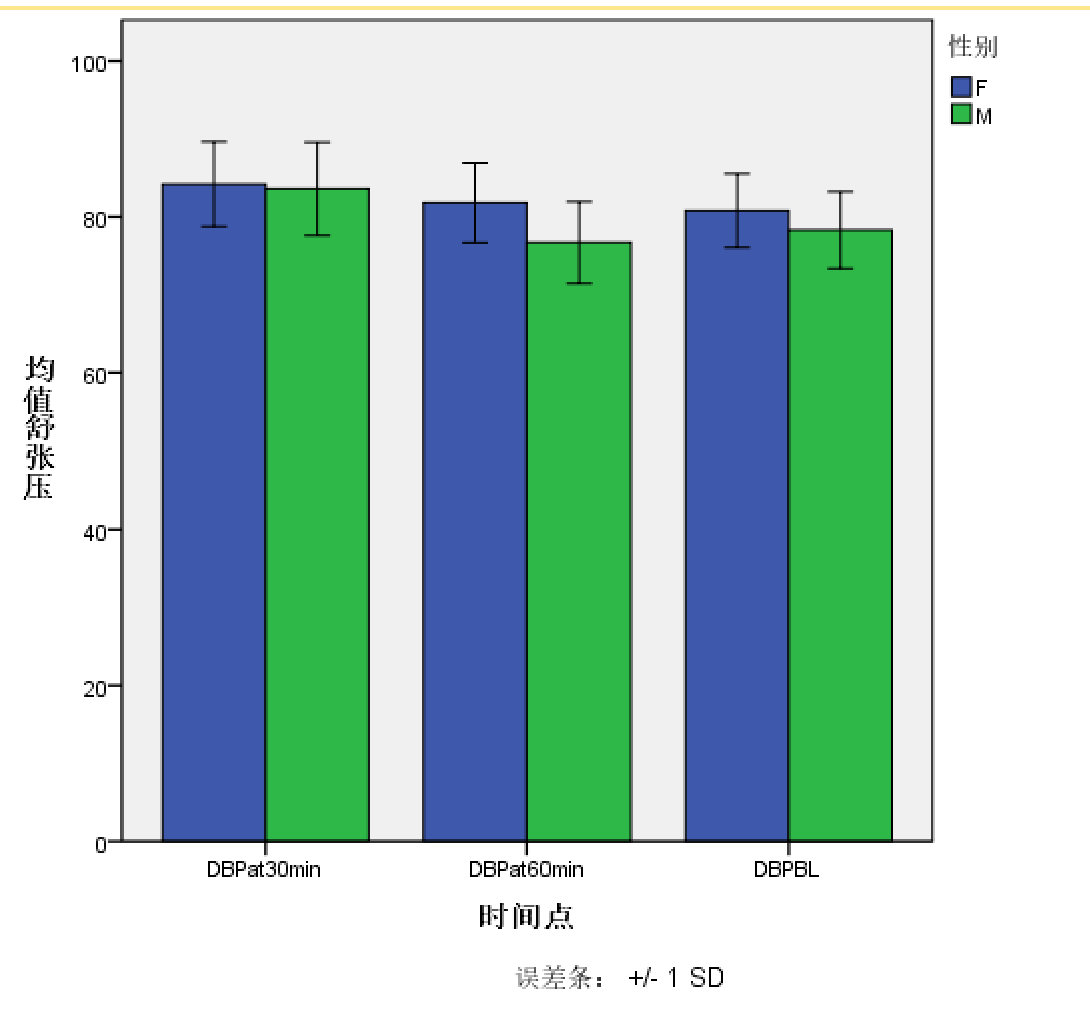
从上一个例子可以看到,时间点作为包含在三个变量列名里面的变量,是没有办法放进类别轴的。所以如果要绘制出上图这样的误差条图,dpi.sav这个数据集需要做出调整,将宽数据格式转换成长数据格式。具体见
小节 4.2.2.4
(宽数据向长数据的转化)
部分。如果复现该节的操作遇到困难,也可以暂时使用已经转换完成的dbp_long.sav来完成本例的操作。在完成了转换以后,剩下的操作方式与
小节 4.2.4.3
(宽数据的复式条形图绘制 分类变量 x 分类变量(以宽数据形式出现) x
定量变量) 就没有差别了。
打开
dbp_long.sav图形
- 旧对话框
- 条形图
- 旧对话框
统计图类型 选择 复式条形图
图表中的数据为 选择 个案组摘要 点击定义打开对话框
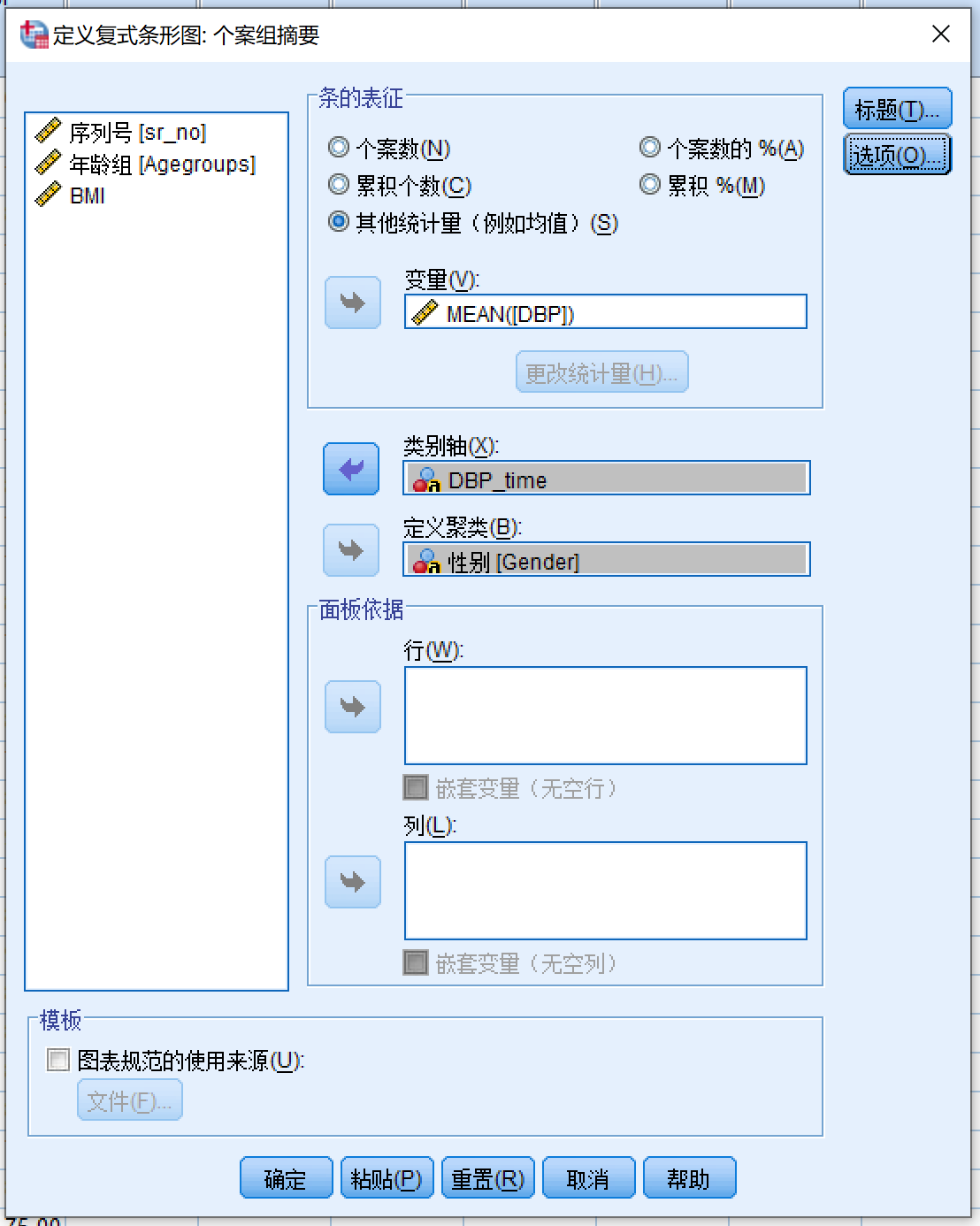
条的表征
- 选择**其他统计量(例如均值)
- 变量源列表 (DBP) >> 变量
- 默认使用均值作为统计量,无需更改统计量
变量源列表 (DBP_time) >> 类别轴
变量源列表 (Gender) >> 定义聚类
点击选项按钮,参考前例设置误差条
显示误差条形图
误差条图的表征
- 选择标准差
- 乘数:1
- 选择标准差
点击粘贴生成语法代码
GRAPH
/BAR(GROUPED)=MEAN(DBP) BY DBP_time BY Gender
/INTERVAL SD(1).4.2.5. 构成比图形
4.2.5.1. 分类变量的条形图
在绘制直方图的时候,我们实际上是将连续的变量划分成若干的组,统计各组频数以后,以频数为纵轴,各组依据上下限在横轴依次展开。如果现在我们面对的是分类变量或者有序变量,以各组频数为纵轴,各组在横轴依次展开,这种图形就是分类变量的条形图。
例3.11 打开titanic.sav,该数据库是泰坦尼克号海难乘客生存数据。请绘制条形图,比较幸存乘客中男性与女性的人数
本例中,生存与否是因变量,性别是自变量
备注:幸存乘客的
Survived变量值为1,性别变量1为男性,2为女性。
- 设置变量标签及值标签。操作方法可参考 小节 2.1.2 (变量视图) 以及 小节 2.1.2.1 (设置值标签的方法)
- 例题需要的是幸存乘客中的数据,因此需要作筛选,只保留
Survived值为1的记录,具体操作方法参考 小节 2.2.5 (筛选) - 绘制条形图
菜单操作方式:
- 图形
- 旧对话框
- 条形图
- 旧对话框
在本题中,我们处理的数据是
分类变量(性别) x 分类变量(生存与否),数据形式是长数据,因此根据
小节 4.2.4.1 (简单误差条形图: 分类变量
x 定量变量) 中的建议,我们应该这样设置:
在 条形图 对话框中 图 4.8:
- 统计图类型 选择 简单箱图
- 图表中的数据为 选择 个案组摘要
点击定义打开 定义条形图 对话框 图 4.9
- 条的表征:由于此处使用频数(也就是生存=1的样本数量)作为纵轴,选择 个案数
- 变量源列表 (sex) >> 类别轴
点击粘贴生成语法代码:
DATASET ACTIVATE 数据集1.
GRAPH
/BAR(SIMPLE)=COUNT BY Sex.思考题. 如果要绘制三个不同舱位等级(
Pclass)中两种性别乘客的幸存者频数统计图,应如何操作?请参考 小节 4.2.4.1 (简单误差条形图: 分类变量 x 定量变量) 中的建议在 图 4.8 中进行合理的选择。
4.2.5.2. 百分比条形图
分类变量绘制条形图时是以类别作为横轴,各类别个案数(频数)作为纵轴。既然可以使用频数,当然也可以使用\(频率=\frac{频数}{总样本量}\),或者说\(构成比=\frac{某一类型频数}{全部类型频数总和}\)作为纵轴。更进一步的,将一个分类变量的不同类型构成比对应的条形图叠在同一个柱子里,这样构成百分比条形图了。下面具体用一个例子来看如何绘制。
例3.12 绘制百分比条形图,比较三种舱位等级乘客中生存与幸存乘客的构成比
本例中生存与否是因变量,舱位等级是自变量
注:这里沿用之前的数据集
titanic.sav,如果之前做了数据筛选,这里记得去除筛选,选用全部数据
菜单操作方式:
- 图形
- 旧对话框
- 条形图
- 旧对话框
打开 条形图 对话框
- 统计图类型 选择 堆积面积图
- 图表中的数据为 选择 个案组摘要
点击定义打开 定义条形图 对话框
- 条的表征:由于此处使用构成比作为纵轴,选择 个案数的%
- 变量源列表 (Pclass) >> 类别轴
- 变量源列表 (Survived) >> 定义堆栈
点击粘贴生成语法代码如下:
DATASET ACTIVATE 数据集1.
GRAPH
/BAR(STACK)=PCT BY Pclass BY Survived.运行代码可见统计图如下图所示:
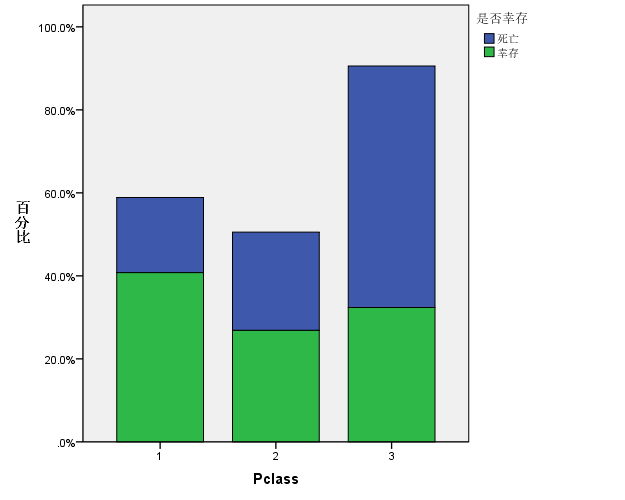
这个图基本符合要求,除了一点:三个百分比条图都是展示生存/死亡构成比,照理说应该高度统一,并且每个类别总的百分比都应该是100%。接下来对统计图进行微调,首先双击统计图:
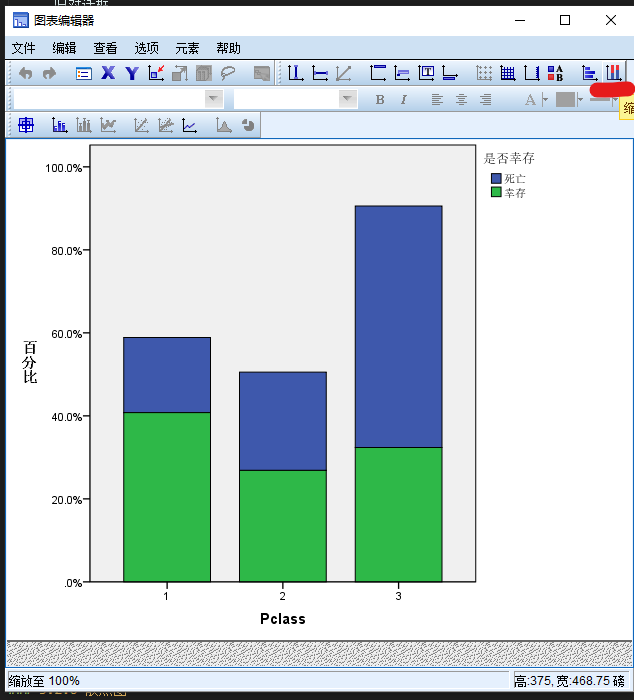
打开 图表编辑器 如上图所示,点击缩放至100%(图中已经用红线标出)按钮,关闭 图表编辑器 窗口。
这样就完成了图形的微调。
思考题:请尝试调换上个例子里面类别轴与定义堆栈的变量,看一下生成的图形有什么不同。
4.2.5.3. 附:饼图
饼图原则上只有一个标度:就是用角度表示各个区块的构成比。加上角度辨别起来并不容易,毕竟我们不可能整天带着量角器去读图,所以饼图不是一个好的统计图形,这里只是展示一下如何绘制。比如说我们想绘制饼图展示各个舱位乘客的构成比
菜单操作方式:
- 图形
- 旧对话框
- 饼图
- 旧对话框
打开 饼图 对话框
- 图表中的数据为:
- 选择个案组摘要
打开 定义饼图:个案组摘要
- 分区的表征
- 选择个案数
- 变量源列表 (Pclass) > 定义分区
点击粘贴获得语法代码
GRAPH
/PIE=COUNT BY Pclass.4.2.6. 散点图
如果说直方图是对于一个变量进行探索性分析的最常用图形之一,那么散点图就是探索变量间关系时最常用的图形之一了。散点图至少可以提供两个标度,分别展示两个变量的数值。接下来我们以anscombe数据集为例演示散点图的绘制方式,同时展示探索性分析的重要性。
打开anscombe.sav数据集,可以看到有三个变量,分别是set,x和y。这个数据集包含了四个子集,每个子集的编号以set表示,x和y是两个定量变量。我们不妨先使用
探索
了解一下各个子集的统计量情况,绘制一下直方图,计算常见的统计量以及进行正态性检验,参考
小节 3.4.2 (使用探索对话框计算)
的操作:
- 分析
- 描述统计
- 探索
- 描述统计
- 变量源列表 (set) > 因子列表
- 变量源列表 (x) > 因变量列表
- 变量源列表 (y) > 因变量列表
- 点击绘制打开 探索:图 对话框
- 描述性:
- 直方图
- 茎叶图
- 箱图:
- 选择 按因子水平分组
- 带检验的正态图
- 点击继续按钮
- 描述性:
- 点击粘贴按钮获得语法代码:
EXAMINE VARIABLES=x y BY set
/PLOT BOXPLOT HISTOGRAM NPPLOT
/COMPARE GROUPS
/STATISTICS DESCRIPTIVES
/CINTERVAL 95
/MISSING LISTWISE
/NOTOTAL.运行语法后可以获得大量输出,这里捡几个重点说一下:
- 首先可以看到x和y在四个子集里的均值,标准差都是一样的,而这两个统计量是我们描述符合正态分布的定量数据时非常重要的两个统计量。
- 从直方图可以看出四个子集的分布并不完全一致,而且某些子集是显著偏离正态分布的。
- 在后续的实验里我们还会学习相关系数以及线性回归,到时还会发现四个子集里x和y的相关系数也是一致的,当然相关系数并不是在每个子集都适用。
接下来看一下四个子集的散点图,我们应该就会理解探索性分析的重要性了
菜单操作方式:
- 图形
- 旧对话框
- 散点/点状 打开 散点图/点图 对话框
- 旧对话框
- 选择简单分布,点击定义按钮,打开简单散点图对话框
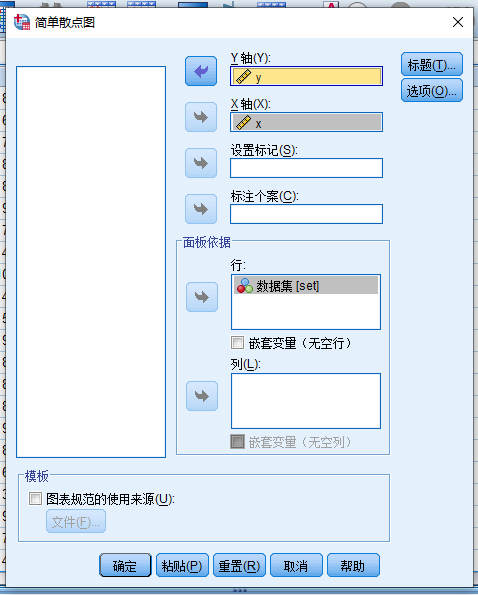
在 简单散点图 对话框中:
- 变量源列表 (y) > y轴
- 变量源列表 (x) > x轴
- 变量源列表 (set) > 面板依据:行
点击粘贴获得语法代码
GRAPH
/SCATTERPLOT(BIVAR)=x WITH y
/PANEL ROWVAR=set ROWOP=CROSS
/MISSING=LISTWISE.运行后生成下图所示散点图
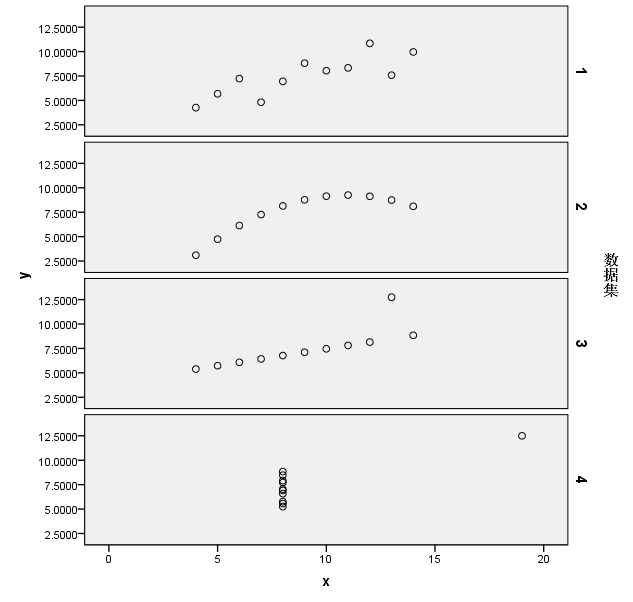
从散点图绘图结果可以看到,尽管四个集合的统计量有相似之处,但是变量之间的关系仍旧可以有很大的区别。这也是为什么(1)统计表,(2)统计图和(3)统计量共同构成了我们描述统计数据的主要工具。
4.3节. 练习题
- 打开
titanic.sav文件,完成以下要求:
1.1 按照下表要求设置变量标签与值标签
| 变量名称 | 变量类型 | 变量标签 | 值标签 |
|---|---|---|---|
| PassengerId | 数值 | 乘客id | |
| Survived | 分类 | 生存 | 0:否,1:是 |
| Pclass | 排序 | 舱位等级 | 1:头等,2:二等,3:三等 |
| Name | 字符 | 姓名 | |
| Sex | 分类 | 性别 | 1:男性,2:女性 |
| Age | 数值 | 年龄 | |
| SibSp | 数值 | 携带兄弟及配偶人数 | |
| Parch | 数值 | 携带父母及子女人数 | |
| Ticket | 字符 | 票号 | |
| Fare | 数值 | 船票费用 | |
| Cabin | 字符 | 仓室名称 | |
| Embarked | 分类 | 登船港口位置 | C: Cherbourg, Q: Queenstown, S: Southampton |
设置变量标签和值标签的方法可以参考 小节 2.1.2 (变量视图) 以及 小节 2.1.2.1 (设置值标签的方法)
1.2 统计不同仓位乘客年龄,船票费用的均值、标准差、标准误,中位数,25%及75%分位数等数据,参考下图中的表格绘制统计表:
1.3 绘制误差条图,比较不同仓位等级的票价平均值。误差条图的绘制可以参考 小节 4.2.4.1 (简单误差条形图: 分类变量 x 定量变量)
1.4 绘制百分比条图,展示不同性别乘客中舱位等级的构成比。百分比条形图的绘制可以参考 小节 4.2.5.2 (百分比条形图)
- 打开
ovid_now.sav数据集
2.1
绘制散点图,分别对新发病例数(new_cases)与人口密度(population_density),以及新发病例数(new_cases)和人均gdp(gdp_per_capita)之间的关联进行探索性分析
2.2 绘制箱式图,展示并比较不同大洲之间新发病例数分布的区别