第3章. 定量资料的描述性统计
本章主要讲解如何计算连续变量的常见描述性统计量,包括假定数据服从正态分布时会使用的平均值,标准差,样本量、均值标准误和置信区间,以及不满足正态分布假定时会使用的百分位数和四分位间距(IQR)等。除此以外一些相对用途较少的统计量,其计算方式也会在本章介绍。除了统计量,直方图与频数表也是常用的展示变量数值分布的工具。描述性统计量与直方图一并构成了对连续变量进行探索性分析的主要工具。在SPSS统计软件中,探索工具和频率工具都可以计算描述性统计量,两者在具体用途和用法上会有一些互补。本章将主要介绍这两个工具的使用方法,同时也会继续应用上一章的一系列工具。
在开始本次实验内容以前,不妨先打开数据文件heart_rate.sav。粗略浏览数据文件就会发现,这个文件包含1个定量变量,140条记录。要怎样才能对这140条记录获得一个初步的认识呢?最常见的三个方向分别是(1)统计表(2)统计图和(3)统计量。这些工具会协助我们更好的对数据获得一个感性的认识,在本次实验中我们会涉及频数表(小节 3.1 (频数表))和直方图(小节 3.2.2 (利用探索对话框绘制))的编制以及定量数据的常用统计量的计算。
3.1节. 频数表
尽管频数表只是直方图的表格形式,但在具体操作上面,两者的区别却非常大。直方图的操作可以用多种图形操作界面工具里的任何一种来完成,但频数表就没那么容易了,它需要综合几个工具,分3步完成。SPSS虽然可以使用 分析 > 描述统计 > 频率 来建立频率表格,但是在使用 频率 对话框以前需要做若干的准备工作,才能制作出符合要求的频数表。频数表的范例如下 表 3.1 :
| 组段 | 组中值 | 频数 | 累计频数 | 频率(%) | 累计频率(%) |
|---|---|---|---|---|---|
| 53~ | 57 | 1 | 1 | 0.7 | 0.7 |
| 61~ | 65 | 5 | 6 | 3.6 | 4.3 |
| 69~ | 73 | 9 | 15 | 6.4 | 10.7 |
| 77~ | 81 | 17 | 32 | 12.1 | 22.9 |
| 85~ | 89 | 21 | 53 | 15.0 | 37.9 |
| 93~ | 97 | 36 | 89 | 25.7 | 63.6 |
| 101~ | 105 | 110 | 1 | 15.0 | 78.6 |
| 109~ | 113 | 126 | 1 | 11.4 | 90.0 |
| 117~ | 121 | 9 | 135 | 6.4 | 96.4 |
| 125~ | 129 | 1 | 139 | 2.9 | 99.3 |
| 133~141 | 137 | 140 | 1 | 0.7 | 100 |
为一个定量变量数据制作频数表的流程包括:
- 重编码
- 设置编码变量的值标签 以及
- 利用 频率 对话框制作频数表。
SPSS的 可视离散化 功能可以协助我们实现(1)和(2)两部分的工作,具体实施方法请阅读 小节 3.1.1 (可视离散化) 。完成重编码后,使用编码变量绘制频数表请阅读 小节 3.1.2 (制作频数表)
3.1.1. 可视离散化
在 小节 2.2.4 (重编码) 中我们提到,在两种情况下需要用到重编码:
- 首先就是字符变量向分类或等级变量的转换,具体方法可以参考 小节 2.2.4.1 (利用 重新编码为其他变量 功能) 和 小节 2.2.4.2 (利用 自动重新编码 功能)。
- 而制作频数表过程中所需要的重编码则属于第二种,使用的工具也与前一种用途所不同。
例2.1 打开heart_rate.sav按照 表 3.1 的组段绘制频数表
菜单操作:
- 转换
- 可视离散化
打开 可视化封装 对话框
- 变量 (heart_rate) >> 要离散的变量
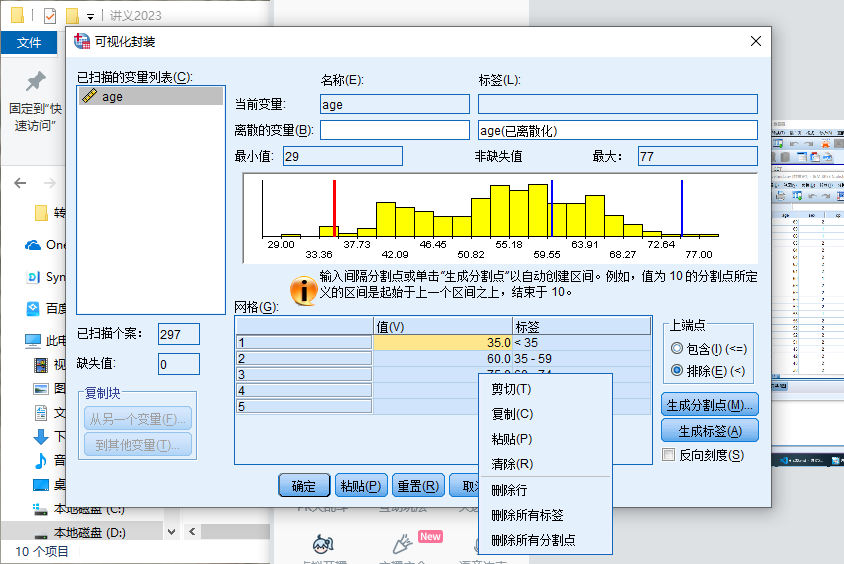
点击 继续 按钮,打开 可视化封装 对话框,如下图所示:
3.1.1.1. 主界面操作
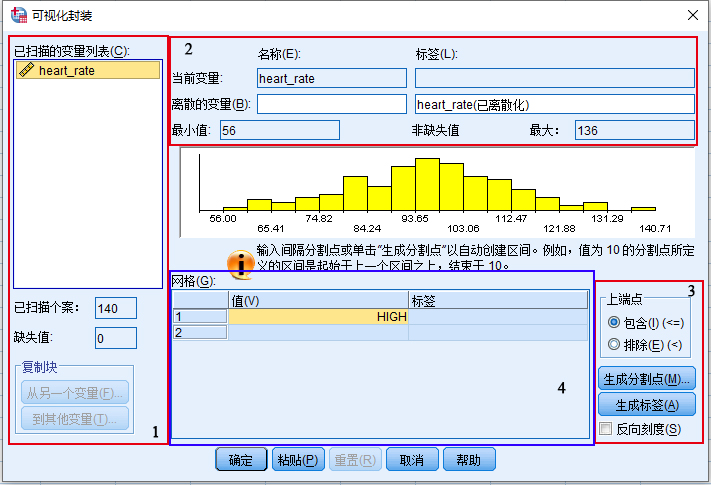
这个对话框 图 3.1 有些让人看得眼花,可以大致将其划分成4个区域:
- 变量选取区
- 离散变量命名区
- 分割点设置区
- 划分详情区
首先,看 图 3.1 中的2区域:
- 要离散的变量 行:
- 名称 列:输入重编码以后变量的名称,如
heart_rate_code - 标签 列:输入重编码以后变量的标签,如 心率编码
- 名称 列:输入重编码以后变量的名称,如
此外,还可以从对话框中看到 heart_rate
变量的最小值是56,最大值是136
接下来,看 图 3.1 中的3区域:
- 上端点 列表:我们做频数表的时候每个组是包括下界,不包括上界的,所以这里需要选择: 排除
- 点击 生成分割点 按钮,打开 生成分割点 对话框 图 3.2
3.1.1.2. 生成分割点
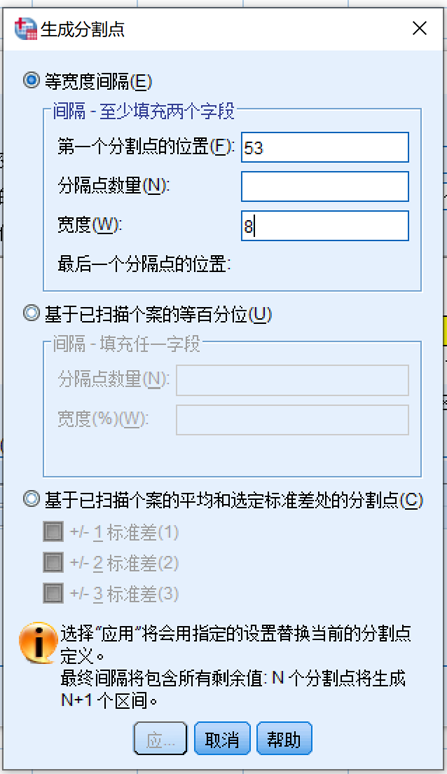
从 表 3.1 中可以看到,本例中频数表将53到141这个区域划分成11个区,组距为8,第一个分割点位于61。
在 生成分割点 对话框中 图 3.2 :
- 选择 等宽度间隔
- 第一个分割点的位置:61
- 宽度:8
- 分割点数量:无需录入,将光标移入空格以后软件会自动计算出10
同时可以看到下方显示最后一个分割点:133,这也就是最后一组的下界
- 点击应用 关闭 生成分割点 对话框,回到可视化封装 对话框
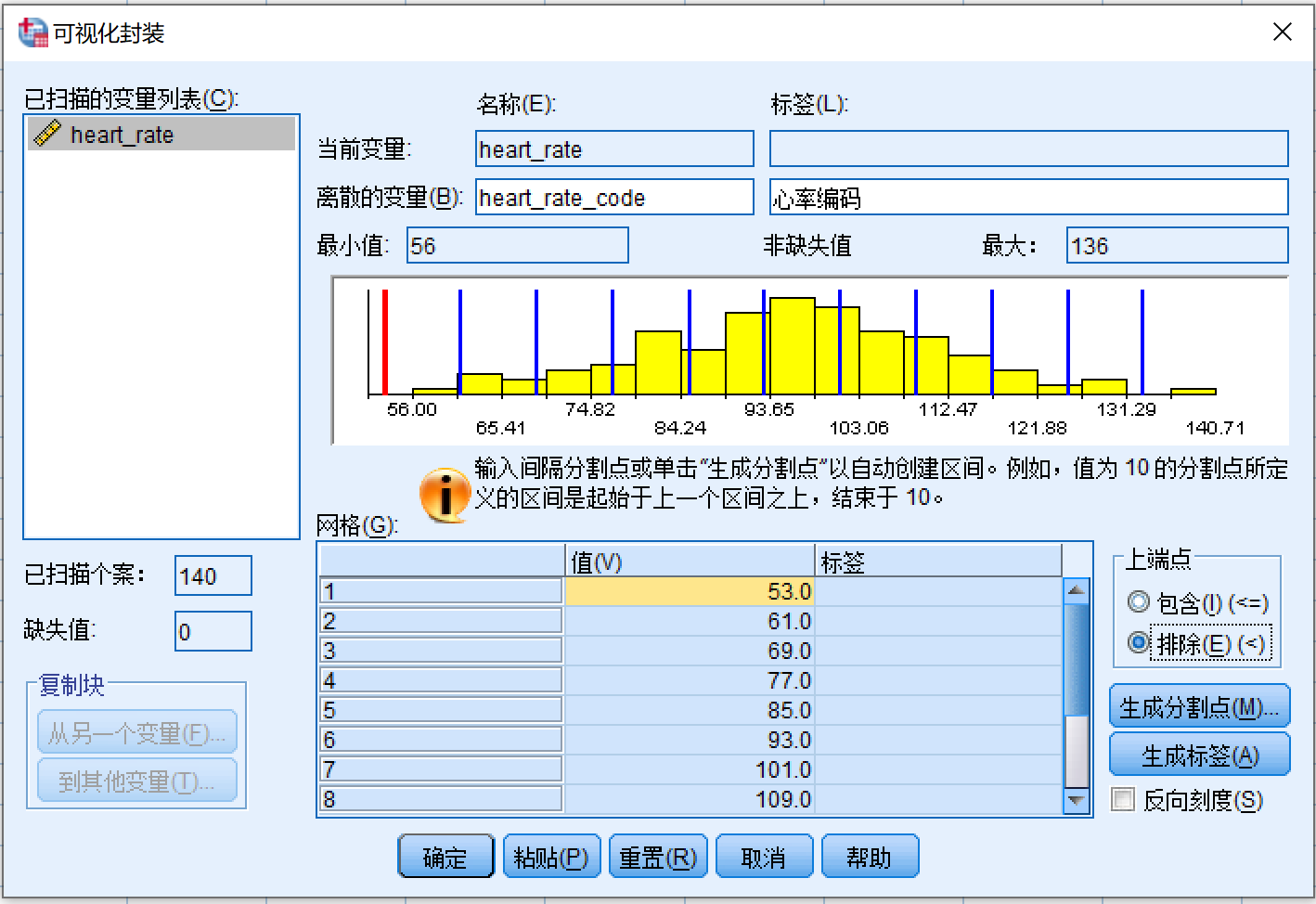
3.1.1.3. 分割点调整以及语法解读
回到主界面后,在 图 3.1
的区域3里还可以点击 生成标签,
SPSS会根据各组的上下界生成 下界 - 上界 形式的标签。
此外,还可以在 图 3.1 的区域4里对分割点作调整。事实上区域4的操作方式就和 图 2.1 里面的数据编辑器一样,可以点击各个单元格进行编辑,也可以在某一行点鼠标右键,图 3.3 在弹出菜单里选择删除该行。
点击 粘贴,生成语法代码如下:
语法代码 3.1: 可视离散化的语法
DATASET ACTIVATE 数据集2.
* 可视化封装.
*heart_rate.
RECODE heart_rate (MISSING=COPY) (133 THRU HI=11) (125 THRU HI=10) (117 THRU HI=9) (109 THRU HI=8)
(101 THRU HI=7) (93 THRU HI=6) (85 THRU HI=5) (77 THRU HI=4) (69 THRU HI=3) (61 THRU HI=2) (LO THRU
HI=1) (ELSE=SYSMIS) INTO heart_rate_code.
VARIABLE LABELS heart_rate_code '心率编码'.
FORMATS heart_rate_code (F5.0).
VALUE LABELS heart_rate_code 1 '< 61' 2 '61 - 68' 3 '69 - 76' 4 '77 - 84' 5 '85 - 92' 6 '93 - 100'
7 '101 - 108' 8 '109 - 116' 9 '117 - 124' 10 '125 - 132' 11 '133 - 141'.
VARIABLE LEVEL heart_rate_code (ORDINAL).
EXECUTE.可以看到代码中包含了RECODE
,VARIABLE LABELS 和 VALUE LABELS
三个部分,以及其他一些辅助语句:
RECODE语句负责对heart_rate变量重编码。可以将该语句和 代码块 2.5 的内容相对比。可以看到两者的基本语法形式是相同的。但由于连续变量向等级变量转换的过程中是一个范围向一个等级值对应的关系,所以本例中定义重编码的方式是区间起点 THRU 区间终点=编码值的形式VARIABLE LABELS和VALUE LABELS的内容与之前看到的并无特别大的区别
到这里,我们已经利用 可视离散化 实现了频数表编制中关键的前两步,后续编制频数表的操作可以参考 小节 3.1.2 (制作频数表) 继续操作。
例2.2 仍旧使用heart_rate.sav数据文件,尝试按照小于50, 50~70,70~90,90~130,130及以上的方式,将heart_rate变量编码为heart_rate_code2`
变量,变量标签仍为心率编码
可以看到新的编码方式各组的组距不全相等,所以无法使用 生成分割点 图 3.2 自动划定各组上下界。
实际上 可视化封装 对话框中,除了可以利用 生成分割点 自动划分区域,也可以在 网络 列表下手动输入分割点,根据例题的要求,我们要增加50, 70, 90, 130共4个分割点
- 网络 列表 也就是 图 3.1 中的4区域
- 值 列:点击空白单元格(也就是HIGH值下方的单元格),输入50,按ENTER录入
- 重复上一步骤录入70, 90以及130
- 在 图 3.1 中的3区域 上端点 内选择排除,并且点击生成标签
- 点击 粘贴 生成语法如下:
语法代码 3.2: 可视离散化的语法: 手动设置分割点
RECODE heart_rate (MISSING=COPY) (130 THRU HI=5) (90 THRU HI=4) (70 THRU HI=3) (50 THRU HI=2) (LO
THRU HI=1) (ELSE=SYSMIS) INTO heart_rate_code2.
VARIABLE LABELS heart_rate_code2 '心率编码'.
FORMATS heart_rate_code2 (F5.0).
VALUE LABELS heart_rate_code2 1 '< 50' 2 '50 - 69' 3 '70 - 89' 4 '90 - 129' 5 '130+'.
VARIABLE LEVEL heart_rate_code2 (ORDINAL).
EXECUTE.与 代码块 3.1 相比,主要的变化就在分割点有所不同,当然,value labels也随之作了变动。
3.1.2. 制作频数表
菜单操作方法:
- 分析
- 描述性统计
- 频率
- 描述性统计
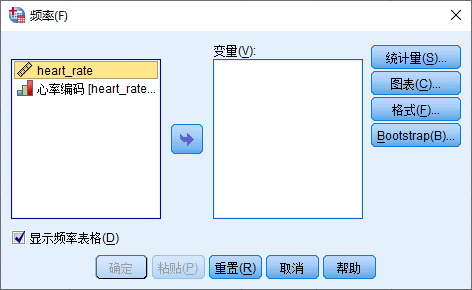
在 图 3.4 中:
- 显示频率表格
- 变量源列表 心率编码[heart_rate_coded] > 变量列表
- 点击 粘贴 按钮生成语法
语法代码 3.3: 制作频率表格
FREQUENCIES VARIABLES=heart_rate_coded
/ORDER=ANALYSIS.运行后获得下表:
| 组 | 频率 | 百分比 | 有效百分比 | 累积百分比 |
|---|---|---|---|---|
| < 70 | 7 | 5.0 | 5.0 | 5.0 |
| 70 - 89 | 38 | 27.1 | 27.1 | 32.1 |
| 90 - 129 | 93 | 66.4 | 66.4 | 98.6 |
| 130+ | 2 | 1.4 | 1.4 | 100.0 |
将输出窗口中的表格复制粘贴进Excel,进一步计算各组中值、累积频率等变量即可完成所需的频数表。
3.2节. 直方图
直方图有多种绘制方式,一般可以在做描述统计的同时绘制直方图。
例2.3 绘制gapminder.sav中lifeExp变量的直方图
3.2.1. 利用频率对话框绘制
菜单操作
- 分析
- 描述性统计
- 频率
- 描述性统计
可以打开如 图 3.4 所示的对话框。与绘制频数表的操作相似
- 变量源列表 (lifeExp) > 因变量列表
- 点 图表,打开 频率:图表 图 3.5 对话框
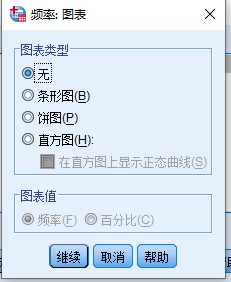
- 图表类型 列表
- 选择 直方图
- 注:如果要同时显示拟合的正态曲线,请选择:
- 在直方图上显示正态曲线
- 选择 直方图
点粘贴产生代码如下所示:
DATASET ACTIVATE 数据集1.
FREQUENCIES VARIABLES=lifeExp
/HISTOGRAM NORMAL
/ORDER=ANALYSIS.3.2.2. 利用探索对话框绘制
- 分析
- 描述性统计
- 探索 打开探索对话框
- 描述性统计
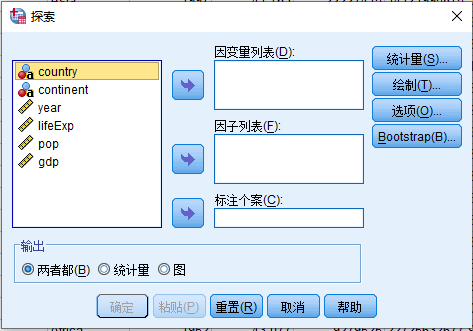
探索 对话框中:
- 变量源列表 (lifeExp) > 因变量列表
- 点 绘制, 打开 探索:图 对话框
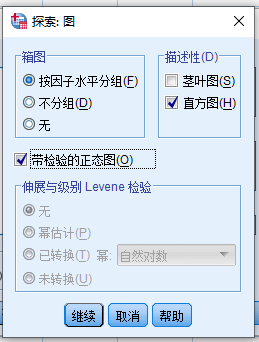
本例中我们不需要箱图,茎叶图,而是需要直方图: - 箱图 列表: - 选择 无 - 描述性 列表: - [ ] 茎叶图 - [x] 直方图 - [x] 待检验的正态图
回到 探索 对话框 图 3.6 - 输出 列表: - 选择 两者都 点 粘贴 ,产生代码如下:
语法代码 3.4: 使用探索工具绘制直方图
EXAMINE VARIABLES=lifeExp
/PLOT HISTOGRAM NPPLOT
/STATISTICS DESCRIPTIVES
/CINTERVAL 95
/MISSING LISTWISE
/NOTOTAL.与 频率 小节 3.2.1 (利用频率对话框绘制) 相比,探索 提供的功能更为丰富,包括:(1)对数据正态性进行检验,(2)可以按照因子对数据进行分组,为各组绘制图形与计算统计量
3.3节. 正态性检验
各种参数性统计分析(t检验,方差分析以及线性回归)都要求变量符合正态分布。评价一个变量是否符合正态分布主要有以下几个工具:
- 直方图
- 箱式图
- QQ图
- 正态性假设检验
描述性统计中的探索功能提供了以上4种工具,其中直方图在 小节 3.2.2 (利用探索对话框绘制) 已经做过描述,而绘制箱式图也可以利用探索一并完成。
例2.4 打开heart_rate.sav,绘制heart_rate变量的箱图、直方图、QQ图,进行正态性检验
与 小节 3.2.2 (利用探索对话框绘制) 中所描述的各项操作相同,首先要打开 探索 对话框, 步骤同前:
- 分析
- 描述性统计
- 探索 打开探索对话框
- 描述性统计
探索 对话框中:
- 变量源列表 (heart_rate) > 因变量列表
- 点 绘制, 打开 探索:图 对话框
在 探索 的 图 对话框 图 3.7 中:
- 箱图 列表:
- 选择 按因子水平分组
- 描述性 列表:
- 茎叶图
- 直方图
- 带检验的正态图
- 点击 继续
回到 探索 对话框, 点击 粘贴 ,获得以下语法代码:
DATASET ACTIVATE 数据集1.
EXAMINE VARIABLES=heart_rate
/PLOT BOXPLOT HISTOGRAM NPPLOT
/COMPARE GROUPS
/STATISTICS DESCRIPTIVES
/CINTERVAL 95
/MISSING LISTWISE
/NOTOTAL.在输出窗口中可以得到直方图、箱式图、QQ图和正态性检验等结果:
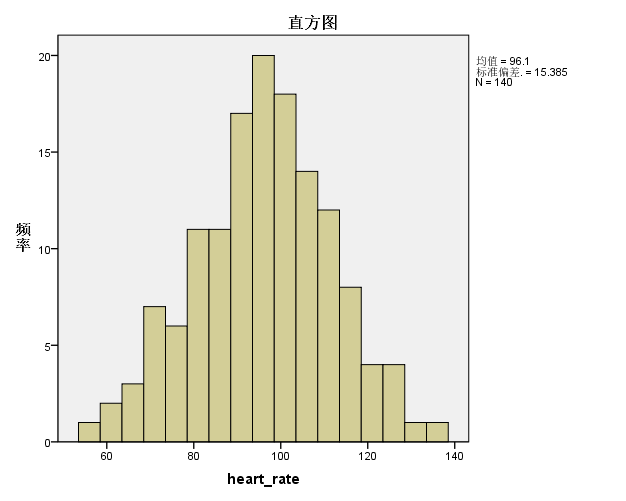 直方图,基本呈左右对称分布
直方图,基本呈左右对称分布
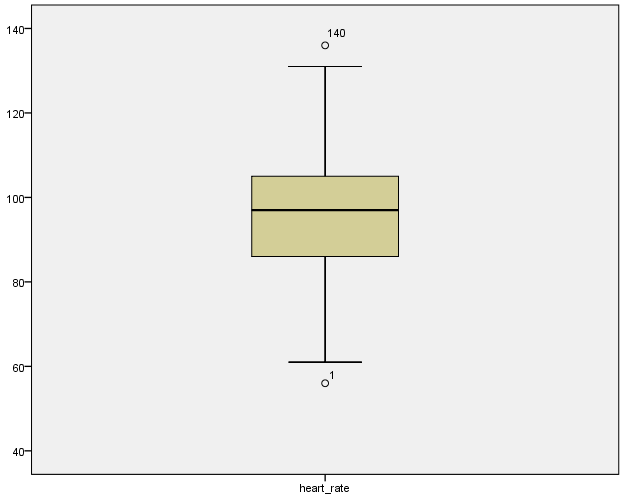 箱式图,中位数,1/4,3/4分位的分布以及上下触须端点位置基本符合正态分布特征,不过有140和1号两个离群点
箱式图,中位数,1/4,3/4分位的分布以及上下触须端点位置基本符合正态分布特征,不过有140和1号两个离群点
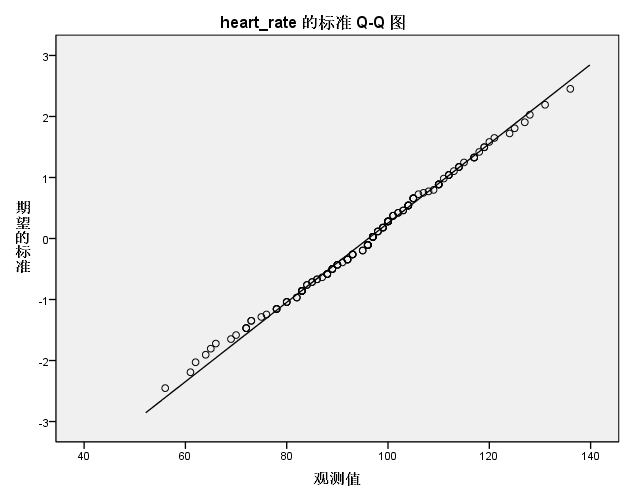 QQ图,斜线代表完全符合正态分布预期的情况,可以看到数据点基本位于斜线附近
QQ图,斜线代表完全符合正态分布预期的情况,可以看到数据点基本位于斜线附近
从上面三种图形可以得出判断,该数据符合正态分布。最终要下决定性的结论,当然需要假设检验的结果,具体的,参见输出窗口中这一表格:
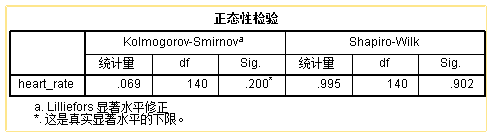
对于样本量大于8,小于50的数据(实际上也适用于更大样本量的情况),Shaprio-Wilk是判断正态性的首选。该假设检验的零假设是数据符合正态分布,所以p值大于预定的\(\alpha\)值时,认为数据符合正态分布。这是需要特别留意的。
注:在上面的例子里,我们只有一个变量:心率,因子不存在 因子 一说。各位同学可以尝试使用gapminder.sav数据,选择某个分类变量(比如大洲)作为 因子 ,然后 小节 3.3 (正态性检验) 中绘制箱式图等统计图形以及计算统计量判断正态分布的操作作为练习。
3.4节. 百分位数,均数,标准差等描述性统计量
在前面的几个小节里我们已经看到了频率和探索两个功能可以给出多个描述性统计量,这里再回顾一下。
例2.5 统计各年度人口的平均值、标准差、1/4分位,中位数,3/4分位,10%分位,90%分位,众数,最小值,最大值和极差
3.4.1. 使用频率对话框计算
注意到例题要求比较各年度数据,而频率对话框不提供根据因子作组比较的功能,所以需要提前 拆分文件。
- 数据
- 拆分文件
在 分割文件 对话框: - 选择 比较组 项目 - 变量源列表 (year) >> 分组方式
点击粘贴生成语法代码:
DATASET ACTIVATE 数据集2.
SORT CASES BY year.
SPLIT FILE LAYERED BY year.运行代码拆分文件后,使用 频率 功能:
- 分析
- 描述性统计
- 频率 打开频率对话框
- 描述性统计
- 变量源列表 (pop) >> 变量
- 点击 统计量 按钮,打开 频率:统计量 对话框
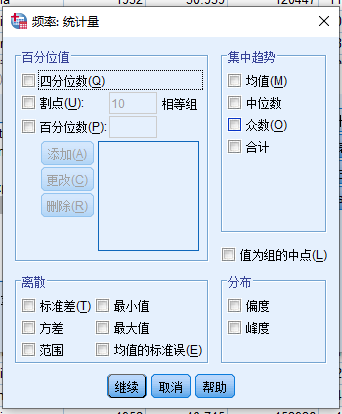
根据例题要求,需要四分位数(1/4,中位,3/4),均值,中位数(已经包含在四分位数中),众数,标准差,最小值,最大值以及范围等项目:
- 百分位值
- 四分位数
- 集中趋势
- 均值
- 中位数
- 众数
- 离散
- 标准差
- 最小值
- 最大值
- 范围 点击继续按钮回到 频率 对话框
此处不需要频数表: - [ ] 显示频率表格
点击粘贴获得语法代码:
语法代码 3.5: 利用频率计算统计量
FREQUENCIES VARIABLES=pop
/FORMAT=NOTABLE
/NTILES=4
/STATISTICS=STDDEV RANGE MINIMUM MAXIMUM MEAN MEDIAN MODE
/ORDER=ANALYSIS.生成的结果会按照年份分组,类似下图:
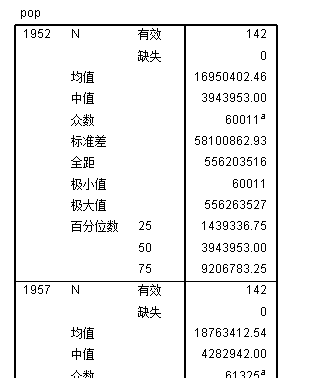
在本分析过程中我们做了拆分文件的操作,无比记住在完成分析后解除文件的拆分状态,否则可能会对后续分析产生影响。具体操作方法可以参考 小节 2.2.2 (拆分)
3.4.2. 使用探索对话框计算
因为探索对话框提供了按因子分组的功能,所以现在不需要再拆分文件了,请参照 小节 2.2.2 (拆分) 中提到的方法取消拆分文件
- 分析
- 描述性统计
- 探索 打开 探索对话框
- 描述性统计
- 变量源列表 (pop) >> 因变量列表
- 变量源列表 (year) >> 因子列表
- 点击 统计量 打开 探索:统计量 对话框
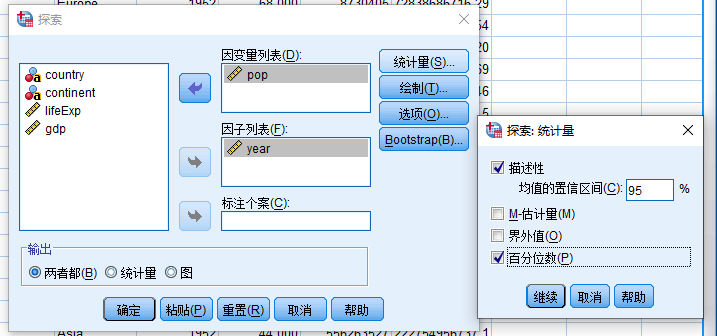
- 描述性
- 百分位数
点击继续
此处我们只需要描述性统计量,所以: - 输出 - 选择 统计量
点击粘贴获得语法代码:
语法代码 3.6: 使用探索计算统计量
EXAMINE VARIABLES=pop BY year
/PLOT NONE
/PERCENTILES(5,10,25,50,75,90,95) HAVERAGE
/STATISTICS DESCRIPTIVES
/CINTERVAL 95
/MISSING LISTWISE
/NOTOTAL.输出结果如下图所示:
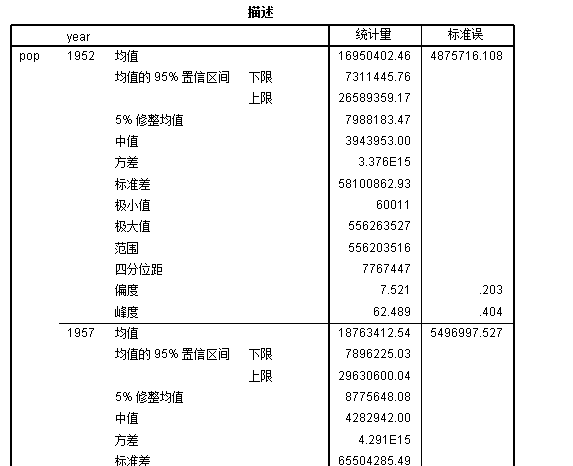
百分位数在另外的百分位数表中显示。事实上我们可能只需要25%,50%和75%这三个分位数,这样的话你可以在 代码块 3.6 中修改第三行的代码,只保留其中的25,50和75三项即可,如 代码块 3.7 所示。
语法代码 3.7: 使用探索计算统计量(百分位只保留4分位数
EXAMINE VARIABLES=pop BY year
/PLOT NONE
/PERCENTILES(25,50,75) HAVERAGE
/STATISTICS DESCRIPTIVES
/CINTERVAL 95
/MISSING LISTWISE
/NOTOTAL.通过上面两种方法的比较可以看到 探索 功能基本可以涵盖 频率 的绝大多数功能。
3.4.2.1. 因变量与自变量(也称作因子)
在前一个例题中,探索对话框中( 图 3.6 ),我们的目的是计算各个年度人口的统计量。随着年份不同,受到新生、死亡、迁入和迁出等等因素的影响,人口数会有所不同;但反过来,人口数的改变是否会造成年份发生变化呢?显然不会。在这样的一个单向的关系中,人口被我们称作因变量,而年份则被称为自变量,或者因子。
在使用SPSS的过程中,我们会经常与自变量和因变量打交道。在一个问题里面区分自变量与因变量是非常重要的。
3.5节. 几何均数
上一小节中我们看到,各种描述性统计量中不包含几何均数,毕竟这不是一个常见的统计量。在SPSS中,个案汇总功能可以计算几何均数。必须要先说明的是,从理论上来说,几何均数只是将原始数据作对数变换以后,求算数平均值,再做逆对数变换的操作。所以尽管SPSS提供了计算几何均数的工具(参见 小节 3.5.1 (使用摘要个案对话框计算几何均数) ),但作者更推荐手动使用计算变量的方式(参见 小节 3.5.2 (使用计算变量途径推导几何均数) )来推算几何均数。
例2.6 打开gapminder.sav,计算各年份,各大洲人口数量的几何均数
请注意,本例中自变量为大洲(continent),因变量为人口。
3.5.1. 使用摘要个案对话框计算几何均数
- 分析
- 报告
- 个案汇总 打开 摘要个案 对话框
- 个案汇总 打开 摘要个案 对话框
- 报告
按照题目要求,需要按照年份(year)和大洲(continent)两个变量进行分组,统计各组人口(pop)变量的几何均数,故有:
变量源列表 (continent) >> 分组变量
变量源列表 (year) >> 分组变量
变量源列表 (pop) >> 变量
显示个案
- 将个案限制到前……
点击 统计量 按钮,打开 摘要报告:统计量 对话框
统计量 (几何均值) >> 单元格统计量
点击 继续 按钮 生成语法如下:
SUMMARIZE
/TABLES=pop BY continent BY year
/FORMAT=LIST NOCASENUM TOTAL
/TITLE='个案汇总'
/MISSING=VARIABLE
/CELLS=COUNT GEOMETRIC.运行后可以看到产生了大量的输出数据,具体到某一个大洲某一年人口的几何均值,会在个案汇总表格的最下方显示,如下图所示:

3.5.2. 使用计算变量途径推导几何均数
可以看到当数据量较大的时候,用 小节 3.5.1 (使用摘要个案对话框计算几何均数) 的方法需要在一堆数据里面找我们需要的内容,比较繁琐。事实上,算数均值是累积求和再除以样本量:
\[\bar{x}=\frac{\sum{x}}{n}\qquad{(3.1)}\]
而几何均值的计算则是累积求乘积再开样本量次方
\[g=\sqrt[n]{x_1*x_2*...x_n}\qquad{(3.2)}\]
利用对数的特性,对 eq. 3.1 式等号左右两边均做对数变换以后可以有:
\[\log_{e}{g}=\log_{e}{\sqrt[n]{x_1*x_2*...x_n}}\qquad{(3.3)}\]
因为\(log_{e}{a*b}=log_{e}{a}+log_{e}{b}\),以及\(log_{e}{\sqrt[n]{a}}=\frac{log_{e}{a}}{n}\),所以上面的式子可以转换成下面的形式:
\[\log_{e}{g}=\frac{\sum{log_{e}{x_i}}}{n}\qquad{(3.4)}\]
到这一步,其实和 eq. 3.1 式就是一样的了,也就是说当对变量做对数变换以后,求新的变量的算数平均值,这个算数平均值就是几何均值对数变换以后的结果了,这时候只要对结果做一个对数变换的逆变换,也就是求e的幂次运算就可以得到几何均值了。
\[g=e^{\log_{e}{g}}=e^{\frac{\sum{log_{e}{x_i}}}{n}}\qquad{(3.5)}\]
回到SPSS操作中, eq. 3.5 式需要我们给变量首先作对数变换,计算平均值后,再计算\(e^{平均值}\)
- 对数变换利用计算变量实现,操作步骤可以参考 小节 2.2.3 (计算变量) :
- 转换
- 计算变量 打开 计算变量 对话框
- 目标变量:输入新变量的名称,如ln_pop 可以利用函数组功能找到所需的对数计算函数:
- 函数组:选择 算术
- 函数和特殊变量:选择 Ln,双击
- 可以看到 数字表达式 里已经出现了
LN(?),光标位于问号处。现在双击 变量源列表 中的pop变量,可见新的表达式变成了LN(pop)当然,也可以直接在数字表达式里面输入LN(pop)
- 使用 频率 计算平均值:
- 拆分文件:
- 数据
- 拆分文件 以
year变量及continent变量做分组方式
- 拆分文件 以
- 频率:
- 分析
- 描述性统计
- 频率 在频率对话框中将
ln_pop纳入变量列表,统计量只保留均值,不需要频率表格输出
- 频率 在频率对话框中将
- 描述性统计
输出结果如下图所示 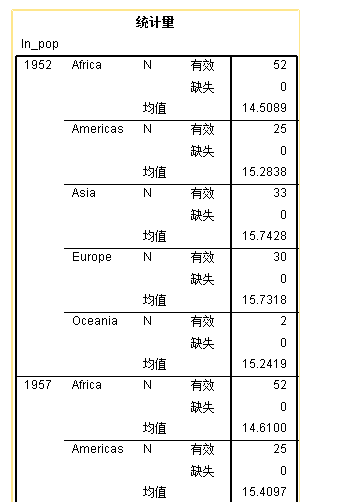 右键点击该 统计量 表格,选择
编辑内容 > 在单独窗口中 打开枢轴表(pivot
table)统计量 对话框
右键点击该 统计量 表格,选择
编辑内容 > 在单独窗口中 打开枢轴表(pivot
table)统计量 对话框 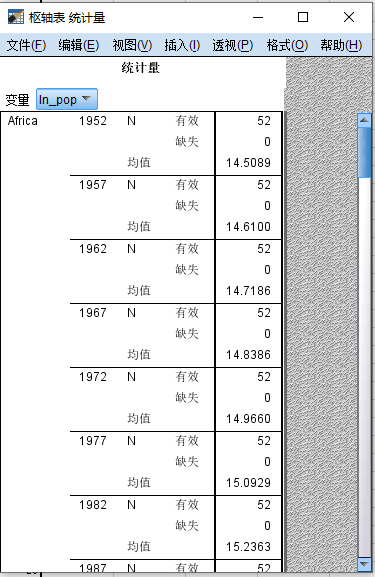
打开 透视托盘 对话框 - 透视 - 透视托盘
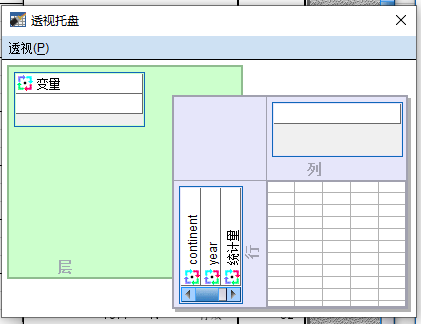
在透视托盘中,将 统计量 从行这一侧拖动到列这一侧,如下图所示
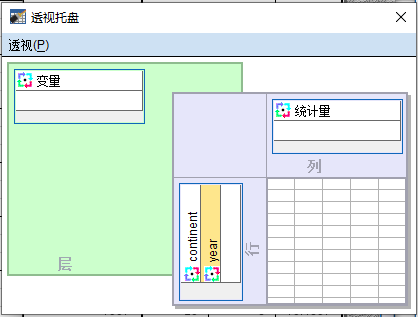
- 关闭 透视托盘
- 关闭 枢轴表 统计量
可以看到统计量表格的排布已经发生了变化,接下来右键点击该表格,选择复制,进入Excel,粘贴
在F列的F5单元格输入公式
=exp(E5),并向下填充,即可获得各个大洲各个年份人口数的几何均值了。
注:Excel的
=exp(E5)公式是取exp的E5单元格值次幂的意思。
3.6节. 练习题
打开 c02_exe_01.sav 数据,完成以下练习:
- 本数据包含3组(group=1,2以及3)受试者的年龄(age),双侧上颌空间(
maxillar_right,maxillar_left)定量变量数据。为了了解各组年龄分布情况,现在需要给各组编制年龄的频数表和直方图。- 注:年龄划分分组依据:[10岁,12岁), [12岁,14岁),[14岁,16岁),[16岁,18岁), 大于等于18岁,编制频数表可参考 小节 3.1 (频数表)
- 在前面的讲解中,heart_rate.sav只有一个变量,现在本问题中引入了分组变量,那么编制频数表的操作是否需要做什么修改?考虑到本题中各组对年龄进行可视离散化的标准是一致的,因此 小节 3.1.1 (可视离散化) 部分所涉及的操作不需要考虑分组的问题。但是在制备频数表的过程中,对编码后的变量按照 小节 3.1.2 (制作频数表) 所涉及的方法编制频数表,此时需要注意按照分组拆分文件。拆分文件方法参考 小节 2.2.2 (拆分)
- 使用探索工具,绘制三组年龄、上颌右侧空间(
maxillar_right),上颌左侧空间(maxillar_left)的直方图、箱式图,结合shapiro-wilk法判断各组的这三个定量变量是否符合正态分布 - 计算三组年龄、上颌右侧空间(
maxillar_right),上颌左侧空间(maxillar_left)三个变量的平均值、中位数、标准差、最大值、最小值、极差、1/4分位,3/4分位数
3.7节. 校对修正
- c02_exe_01.sav 中,年龄最好是整数