第6章. 方差分析
本章节实验讲义主要内容包括:
- 完全随机设计方差分析
- 随机区组方差分析
- 析因方差分析
在每个小节中,我们会首先讲述方差是如何分解的,然后再开始SPSS软件操作和结果解读的讲解。至于统计建模这一路径,我们会在后续的实验中讲解。
6.1节. 完全随机设计方差分析
例 5.1 研究大豆对于缺铁性贫血的作用,使用大鼠建立缺铁性贫血模型,36只模型鼠随机分为三组,分别使用三种饲料(1组使用普通饲料,2组使用10%大豆饲料,3组使用15%大豆饲料)喂养一周后测量血红细胞数(\(\times 10^{12}/L\)),分析三种喂养方式是否存在差异?数据见链接:6-1.sav
- 根据例题说明,设置好group变量的值标签(参考 小节 2.1.2.1 (设置值标签的方法) ) 以及度量标准
- 检验是否符合正态分布 (参考 小节 3.3 (正态性检验) )
- 进行方差分析:本例实验设计中,红细胞数是指示结局的因变量,而分组所代表的不同喂养方式则是自变量,实验中没有设置区组,可以进行完全随机设计的方差分析。
- 分析
- 比较均值
- 单因素ANOVA 打开对话框 图 6.1
- 比较均值
- 变量源列表 (rbc) > 因变量列表
- 变量源列表 (group) > 因子
- 点击两两比较设置Post Hoc检验:
- 假定方差齐性 列表下:
- Tukey (如果没有特定的对照组,可以选择Tukey作为组间比较的方式)
- Dunnett
(如果有特定的对照组,可以选择Dunnett方法)
- 控制类别:
- 根据对照组为第几组选择,本例中对照组是第一组(使用普通饲料),因此选择第一个
- 控制类别:
- 检验列表:一般选择双侧检验
- 显著性水平:输入预设的\(\alpha\),这里继续保持默认的0.05
- 点击继续
- 假定方差齐性 列表下:
- 点击选项:
- 统计量列表下:
- 描述性
- 方差同质性检验
- Welch
- 均值图
- 点击继续
- 统计量列表下:
- 点击粘贴获取语法:
ONEWAY rbc BY group
/STATISTICS DESCRIPTIVES HOMOGENEITY
/PLOT MEANS
/MISSING ANALYSIS
/POSTHOC=TUKEY DUNNETT (1) ALPHA(0.05).运行语法获得以下结果:
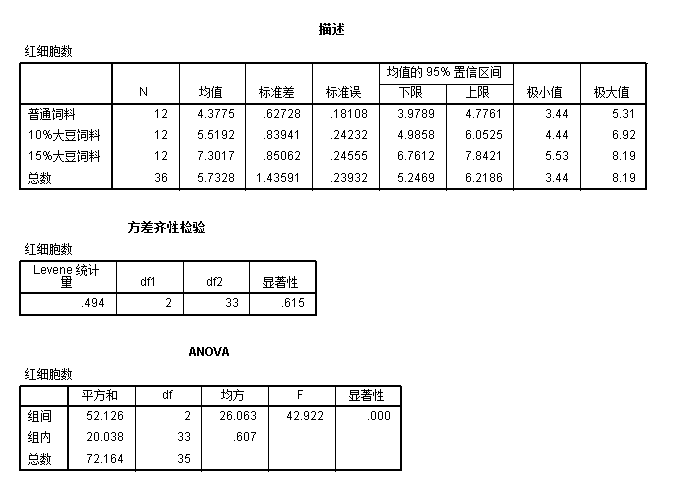
- 描述表展示了分组变量的三个类别各自对应的红细胞数均值及标准差
- 方差齐性表用于验证是否符合方差齐性假定
- ANOVA表则给出了组间、组内以及总的SS,自由度,MS以及计算的F值和p值
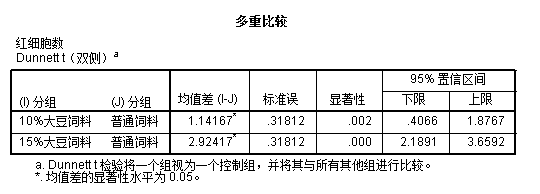
dunnett法设置了对照组,所以组间比较数从\({3 \choose 2}=3\)减少到了2。
6.2节. 随机区组设计方差分析
区组作为控制手段,目的在于减少随机抽样为结果带来的变异,可以作为随机因素纳入模型。具体实现方法如下:
例5.2 打开数据6-2.sav,该数据研究补钙药物对绝经期妇女骨密度的影响,按照年龄对受试者划分了7个区组,每个区组4名受试者随机分为4组,按照4个剂量服药观察(第4组是对照组)。经过一年治疗后测定期骨密度的变化值。尝试分析四种剂量组是否存在差异?
- 分析
- 一般线性模型
- 单变量 打开对话框,如下图所示:
- 一般线性模型
- 变量源列表 (bone_density) > 因变量
- 变量源列表 (group) > 固定因子
- 变量源列表 (block) > 随机因子
区组因子(block)不仅应作为随机因子纳入模型,事实上由于实验设计,随机因子和固定因子的交叉项实际上是无法,也不应该纳入方差分析的。但SPSS会默认将两者的交叉项纳入分析,如果我们现在直接点击确定按钮可以看到下表所示的结果:
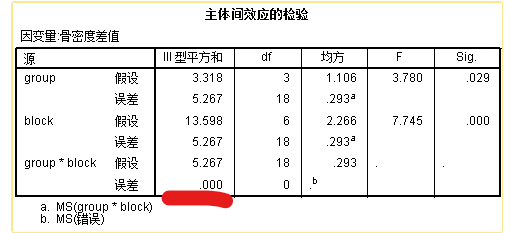
思考:可以看到区组因子和随机因子的交叉项
group*block对应的误差项SS是0,为什么呢?
所以,对于随机区组设计,在设定了因变量、固定因子以及随机因子以后,接下来还需要进行如下设置:
点击模型按钮
- 指定模型 列表
- 选择设定
- 因子与协变量 (group) > 模型
- 因子与协变量 (block) > 模型
- 构建项
- 选择主效应
- 在模型中包含截距
- 点击继续按钮 设置如下图所示:
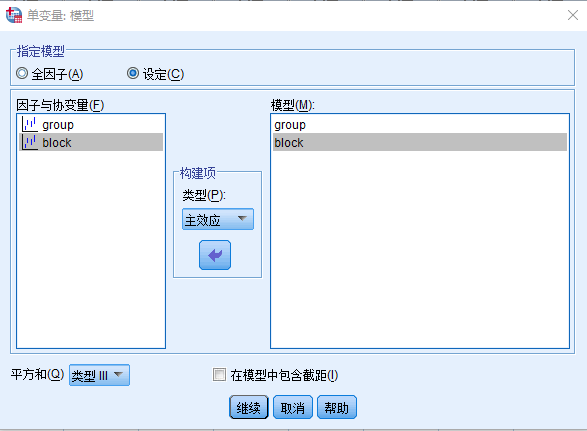
在不考虑交叉项的前提下,平方和选择类型III还是类型I影响不大,但是在 小节 6.3 (析因方差分析) 中我们会看到两种方法的不同。
- 指定模型 列表
点击绘制
- 因子 (group) > 水平轴
- 点击添加
- 点击继续
点击两两比较
- 因子 (group) > 两两比较检验
- 假定方差齐性 列表
- Dunnett
- 控制类别:选择最后一个(本题中对照组是第四组)
- Dunnett
- 点击继续
点击选项
- 输出 列表
- 描述统计
- 显著性水平:仍旧保持0.05
- 点击继续
- 输出 列表
点击粘贴生成语法:
UNIANOVA bone_density BY group block
/RANDOM=block
/METHOD=SSTYPE(3)
/INTERCEPT=EXCLUDE
/POSTHOC=group(DUNNETT)
/PLOT=PROFILE(group)
/PRINT=DESCRIPTIVE
/CRITERIA=ALPHA(.05)
/DESIGN=group block.输出结果中,主要的结果包括主体效应检验:
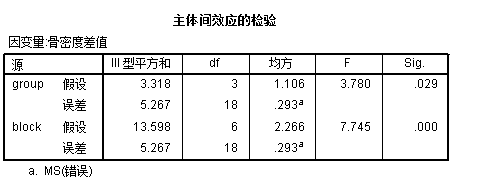
从结果中可以看到组间存在差异(\(F_{3,18}\)=3.78,p=0.29),说明不同的补钙剂量治疗效果不全相同,可以进一步参考组间比较的结果进行分析。block来源的F值更大,p值更小,但该因素并不是我们研究设计里的主体,这个结果只能印证研究设计中,按照年龄将受试者进行分组是正确的。
我们不妨对这个数据进行单因素方差分析,参考 小节 6.1 (完全随机设计方差分析) , 只考虑分组一个自变量:
- 分析
- 比较均值
- 单因素ANOVA 打开单因素方差分析对话框,如 图 6.1 所示
- 比较均值
- 变量源列表 (bone_density) > 因变量列表
- 变量源列表 (group) > 因子
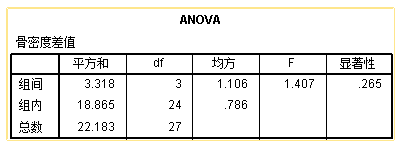
可以看到在未考虑年龄因素划定区组的时候,组间差异相较于组内差异会在统计学上显得无意义。请注意,不管是单因素ANOVA还是随机区组设计ANOVA,分组因素的平方和都是3.318,引入区组以后,只是从原先的组内SS:18.865中划出来了13.598,使得现在的误差项减少到了5.267,由于误差项(也就是F值的分母部分)减少了,随机区组设计里对分组进行的方差分析获得了阳性的结果。
下图展示了组间比较的结果:
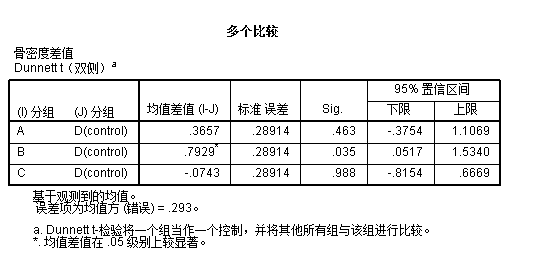
可以看到只有B组与对照组之间的差异是有显著性的。
6.3节. 析因方差分析
当我们要同时考虑多个自变量对因变量影响的时候,需要使用析因方差分析。接下来以例3进行讲解。
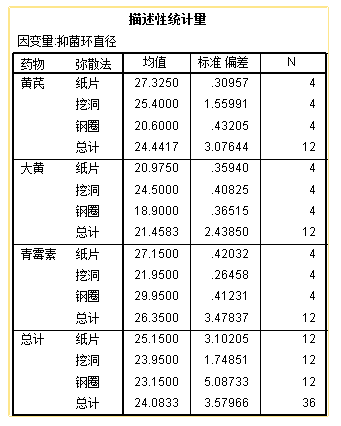
例5.3 在药物敏感性试验中,需要比较三种药物(黄芪,大黄和青霉素)的抑菌效果,研究者使用了三种弥散法(纸片、挖洞以及钢圈),以抑菌环的直径作为观察指标,研究结果见数据6-6.sav。尝试分析比较三种弥散法的效果是否有差异。
- 分析
- 一般线性模型
- 单变量 打开下图所示对话框
- 一般线性模型
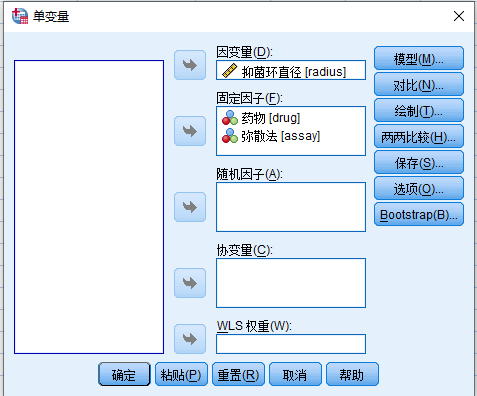
变量源列表 (radius) > 因变量
变量源列表 (drug) > 固定因子
变量源列表 (assay) > 固定因子
点击模型按钮,打开模型对话框
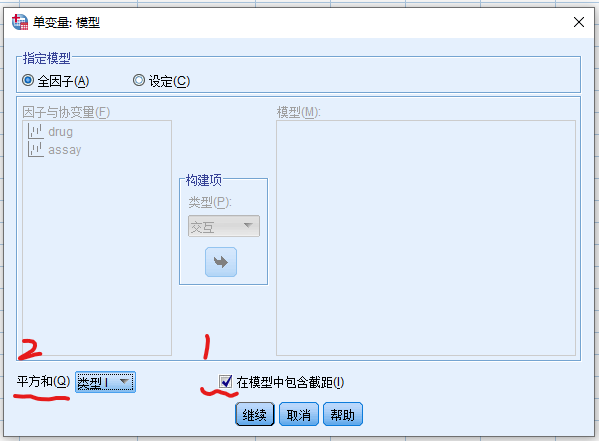
- 指定模型 列表
- 选择全因子
- 在模型中包含截距
- 注1:在区组随机设计方差分析中,可以选择或者不包含截距。但在析因方差分析里,必须选择包含截距,因为需要针对截距对模型进行校正
- 注2:本例中各小块样本量相同,都是4,所以平方和可以选择III类。但如果小块样本量不同(即非平衡设计),则平方和应选择I类。读者可以打开bmi.sav,以dis和gender作为固定因子,bmi为因变量,看一下I类平方和与III类平方和的异同。
- 点击继续按钮回到上一级对话框
接下来再对其他部分进行设置
- 点击绘制
- 因子 (assay) > 水平轴
- 因子 (drug) > 单图 > 注:这里一般使用主要分析的因子作为水平轴,额外的因子放在图里标度,也就是单图里
- 点击添加
- 点击继续
- 点击两两比较
- 因子 (assay) > 两两比较检验
- 假定方差齐性 列表
- Tukey
- 点击继续
- 点击选项
- 输出 列表
- 描述统计
- 方差齐性检验
- 显著性水平:仍旧保持0.05
- 点击继续
- 输出 列表
- 点击粘贴生成语法:
DATASET ACTIVATE 数据集2.
UNIANOVA radius BY drug assay
/METHOD=SSTYPE(3)
/INTERCEPT=INCLUDE
/POSTHOC=assay(TUKEY)
/PLOT=PROFILE(assay*drug)
/PRINT=HOMOGENEITY DESCRIPTIVE
/CRITERIA=ALPHA(.05)
/DESIGN=drug assay drug*assay.运行输出结果中主要的几个表格如下:
描述性统计量:
方差齐性结果:
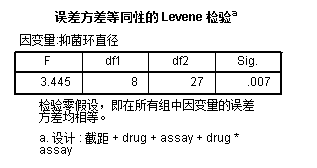
不满足方差齐性要求,考虑到该例题样本量较小,这也是难以避免的结果。目前暂时继续分析
模型评估:
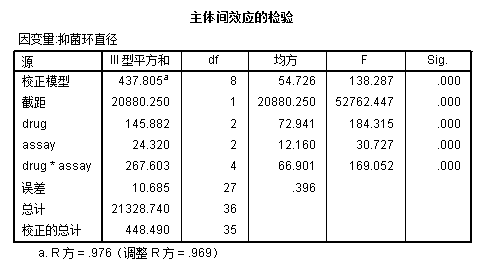
与 小节 6.1 (完全随机设计方差分析) 的ANOVA表相比,这个表格毫无疑问更加复杂。这里面包含了五个F值,这里分别说一下:
- 校正模型:这一项表示剔除了截距进行校正以后,同时考虑了药物,弥散法以及两者相互作用三个因素以后的模型在总SS所占的作用
- drug、assay以及drug*assay:三个部分共同构成了校正模型(可以自行验算:145.882+24.320+267.603=437.805),各自分别有F值和p值。从结果来看,三个部分都具有统计学意义
- 截距:该部分本身属于校正项,不具有实际上的意义。
本例结果中可以看到药物与弥散法的交叉项是具有统计学意义的,对于这种情况需要进一步按照具体情况分析。先看一下均值图:
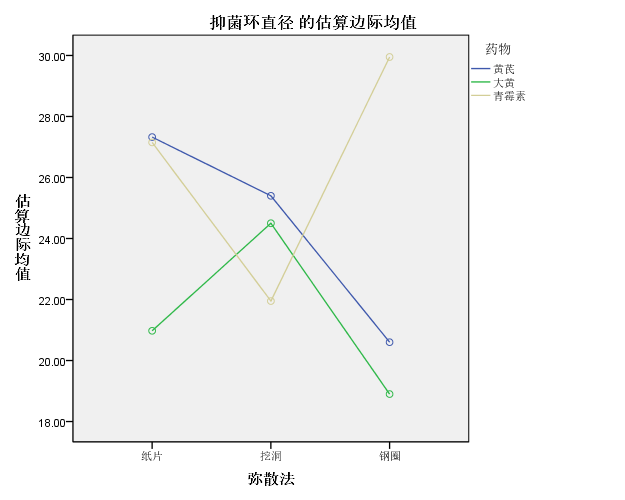
可以看到三种药物的均值折线图不仅没有较好的平行,而且出现了严重的交叉(从模型分析表格也可以看到,交互项的F值甚至大于两个因素中的任何一个)。其中青霉素药物在三种弥散法的趋势是和另外两种弥散法完全相反的。对于这种无法忽视的交互作用,首先应该从专业角度考察实验设计是否存在问题。另外,如前所述,本例数据样本量较小,且方差齐性假定未得到满足,这些都会对统计结果产生影响。
当交互项(drug*assay)确实存在统计学意义,但其影响并不甚重要时,可以尝试比较下面几种模型的调整R方来选择最好的模型(以调整R方最大的为优先)
比如现在有因素A与B作为自变量,Y为因变量
- Y~A+B (A,B作为固定因子,模型设定为加入A,B的主因素模型)
- Y~A+B+A*B (A,B作为固定因子,模型选择全因素)
- Y~A*B (A,B作为固定因子,模型设定为AB交互因素)
如果模型3的调整R方较小,可以考虑交互项影响不大。
6.4节. 方差分析结果的汇报
以完全随机设计方差分析为例:
三种饲料喂养后大鼠血红细胞数存在统计学差异(\(F_{2,33}\)=42.92,p<0.001),具体数据见表2,对三种饲料进行组间比较可得,10%大豆饲料与对照组(MD=1.14, p=0.002)和15%大豆饲料与对照组(MD=2.92,p<0.001)均存在差异。

6.5节. 正交试验设计
在药学实验中,往往有多种影响结果的因素,每个因素又可以有多种取值,如果遍历所有可能那么实验工作量会非常大,而通过正交试验设计则可以减少所需的实验组数。
例5.4 研究者尝试寻找合成一种化合物的优化方法,研究者准备在三种反应温度(20摄氏度,35摄氏度,40摄氏度),三种底物浓度(40%,60%,80%)和三种酶(A酶,B酶,C酶)中寻找最优方案,请协助研究者拟定正交试验方案。
- 打开spss,新建数据文件
- 数据 > 正交设计 > 生成,打开生成正交设计对话框
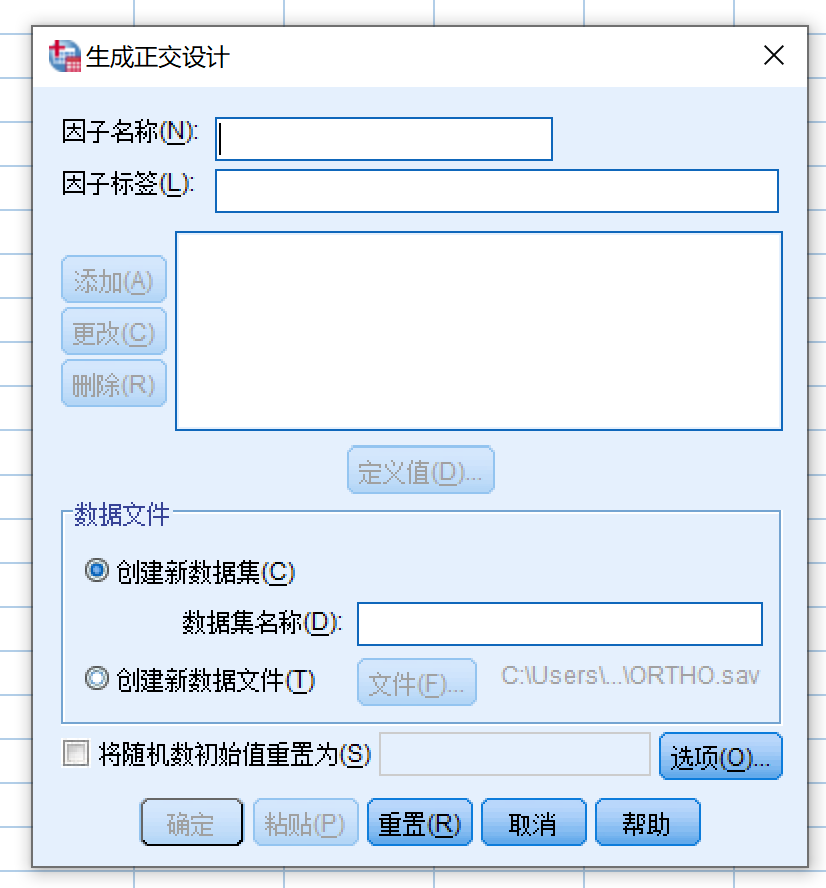
- 依次加入三种因素,以反应温度为例:
- 反应温度
- 因子名称: temperature
- 因子标签: 反应温度
- 点击添加
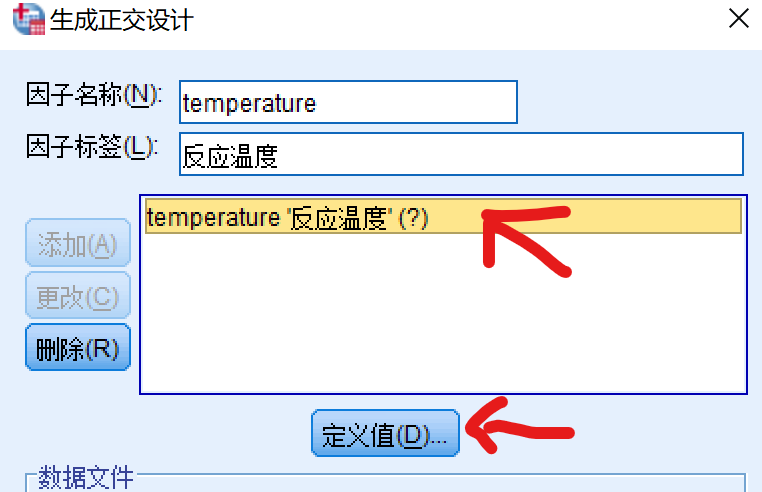
- 点击新添加的 temperature ‘反应温度’ (?),然后点击定义值,打开生成设计:定义值对话框
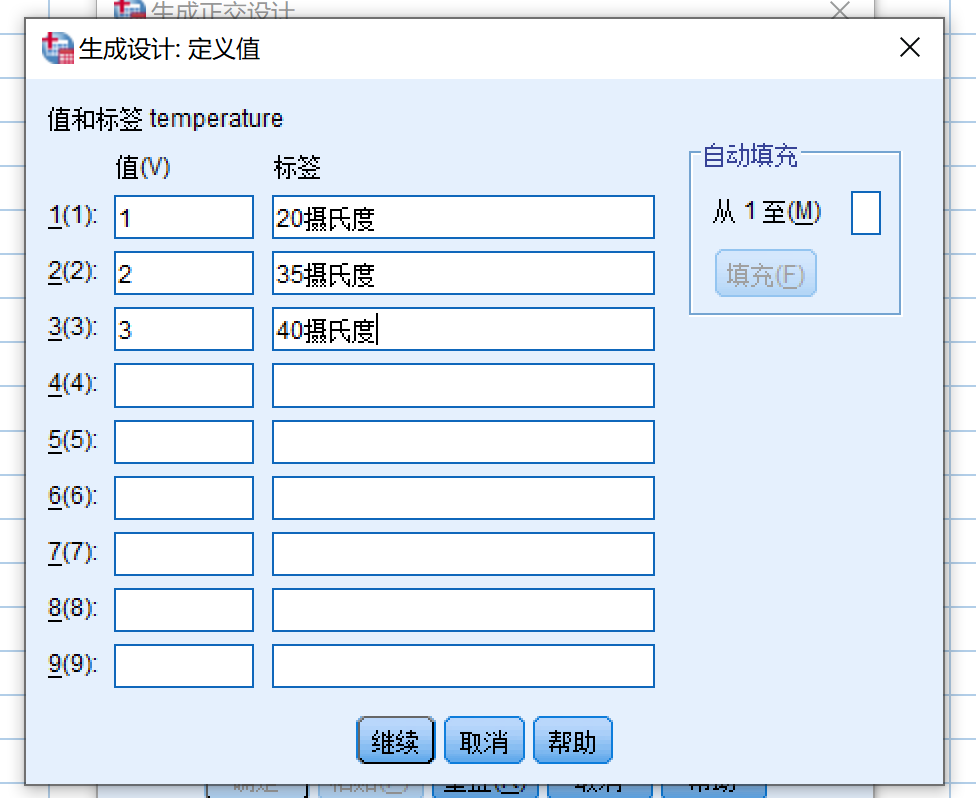
- 如上图所示,由于温度有三个水平,依次录入1,2,3,并设置对应的值标签,点击继续
- 其他两个因素以此类推
- 反应温度
- 定义数据文件名:
- 数据文件
- 选择创建新数据集
- 数据集名称:录入数据集名称,如design
- 选择创建新数据集
- 数据文件
- 点击确定运行后生成数据集如下:
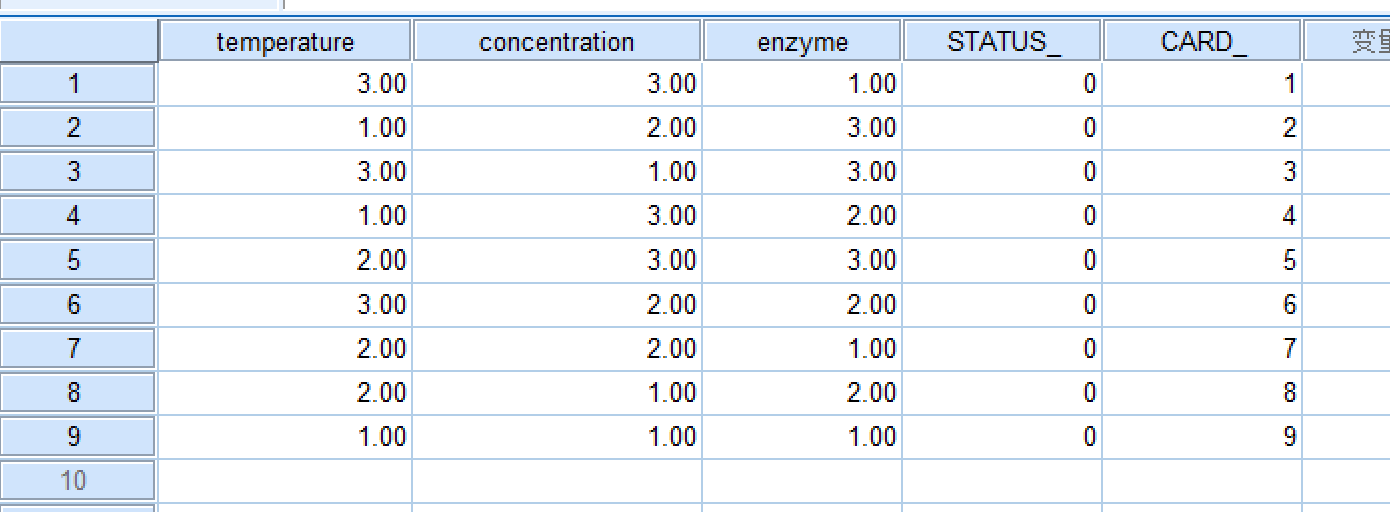
与\(3^3=27\)个实验相比,现在缩减到了9种实验方案。请问:如果每种实验方案需要的样本量是4,那么完成9种方案需要的样本量是多少?
答案是36,不是9
- 显示正交设计方案:现在虽然数据文件里已经列举了9种方案里四个因素的取值,但是看起来还是不大好懂。最好是使用显示方案的功能将方案整理出来
- 数据 > 正交设计 > 显示,打开显示设计对话框
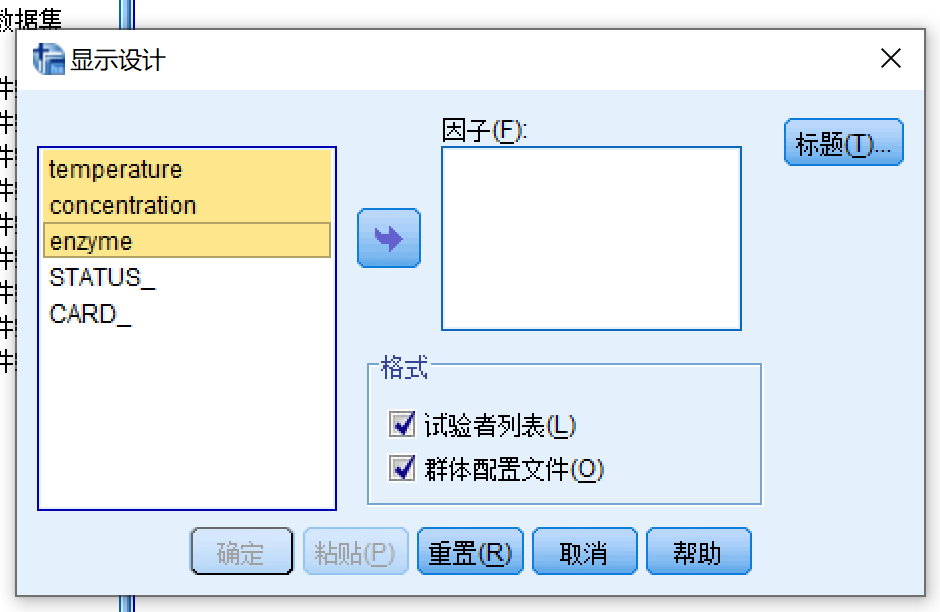
- 将三个因素变量(temperature,concentration和enzyme)移动到因子一栏
- 格式
- 试验者列表
- 群体配置文件
- 点击确定获得输出结果
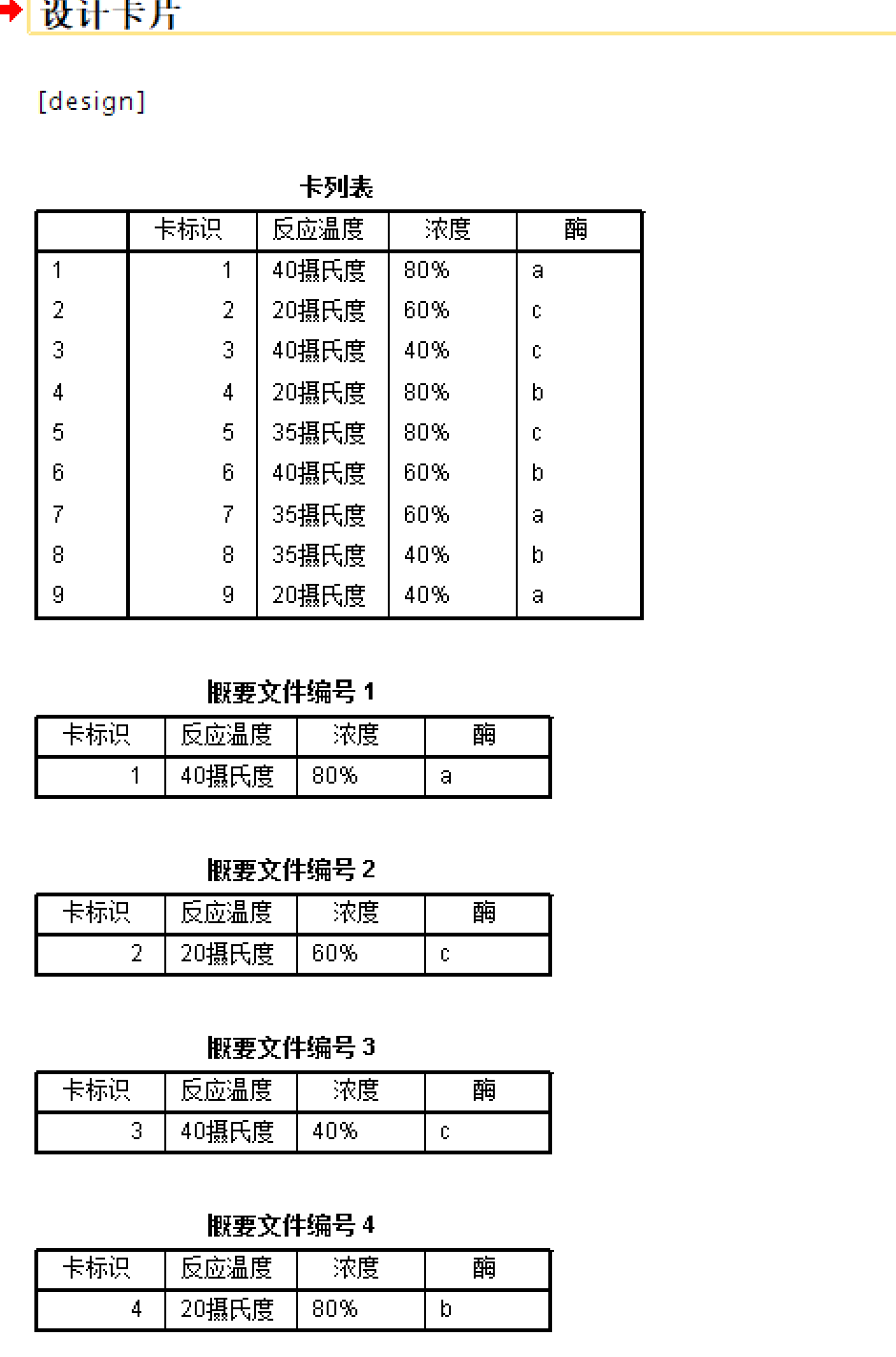
6.6节. 练习题
- 打开
ch5_exe_1.sav。数据为使用三种教学方法后,学生的考评成绩。- 本题数据属于宽数据,参照 小节 4.2.2.4 (宽数据向长数据的转化) 将其转换为长数据
- 不考虑IQ区组的情况下,按照完全随机设计方差分析的流程分析三种教学方法所得的考评成绩是否存在差异
- 考虑IQ区组,进行区组方差分析,评价三种教学方法所得的考评成绩是否存在差异,并进行组间比较。
- 打开
ch5_exe_2.sav。研究者将受试者分为三组,分别使用三种不同的方法干预(第三组为对照组)。- 按照以下要求进行数据预处理:
- 设置变量标签:age: 年龄,gender:性别,group:分组,score:测评得分
- 设置值标签:
- 性别:1:男,2:女
- 分组:1:认知治疗,2:认知治疗+物理治疗,3:常规治疗
- 将年龄划分为25岁以下,25岁及以上两组,重编码后的变量名为
age_coded,并设置相应的值标签
- 只考虑分组这一个自变量,考察不同分组所得的效果评分(
score)是否存在差异 - 研究者根据专业知识,认为年龄以及性别也会对治疗的效果产生影响,请进行析因方差分析,考察以下问题:
- 年龄与治疗分组,性别与治疗分组之间是否存在交互作用?
- 加入年龄以及性别两个因素以后,不同治疗组所得的效果评分是否存在差异?这一结论与第二问所得的结论是否一致?
- 只考虑分组因素的模型,其调整R方是多少?年龄+性别+分组析因方差分析模型的调整R方是多少?
- 按照以下要求进行数据预处理:
- 某研究者需要开展一个4因素的实验,具体包括温度(20,30,38摄氏度),反应时间(1分钟,2分钟,5分钟),底物浓度(10%,20%,40%)以及催化剂(A,B),请利用SPSS的正交试验设计功能给出设计方案。