第5章. 参数估计与t检验
本章节主要内容是各种统计量的置信区间估计以及三种t检验的实现方式与结果解读。此外,本讲义在第一到第三章篇幅较长,而从本章开始篇幅相对会变短。这是因为统计分析工作里,最麻烦的其实是数据的准备与清理,而进入假设检验以及建模工作以后,更多的工作是直接交给软件去完成,操作步骤反而变得简单了。
需要注意的是,在进行本章的各种t检验之前,都应该首先通过 探索 评判数据是否符合正态分布(参考),对于显著偏离正态分布的数据,不建议进行t检验
5.1节. 使用Bootstrap法估计各种统计量的置信区间
在医学统计学的理论学习中,我们已经学过:对于符合正态分布的定量变量,可以通过样本均值估算总体均值的置信区间,对于二分类变量,在能够向正态分布近似的情况下也可以估算总体率的置信区间。但如果我们想估算标准差,中位数,5%分位数或者其他统计量的置信区间时,又应该如何计算呢?显然,我们不可能给每一个统计量都去找一个置信区间计算公式(尽管这是一个可行的办法)。我们需要的,是一个相对而言准确性可以接受,且更泛用的方法,就像是概率运算问题里的“遇事不决,蒙地卡罗”一样。
在讲操作以前,我们先看一下Bootstrap法的工作原理。根据随机抽样的假设,样本里的每一项都是总体的一分子,且具有同等的代表性。如果我们要了解某一个统计量的变动范围(这一变动来自抽样误差),进而反推参数的置信区间,最理想的手段当然是通过重复的随机抽样。问题是这样的成本太高了,Bootstrap法则是退而求其次,通过对样本进行重复抽样(每一项可以多次被抽取,但最后组成的新样本,其样本量不变),改变原样本中各项的代表性,从而达到模拟从总体重复抽样的作用。
5.1.1. Bootstrap + 频率
例4.1 打开数据文件heart_rate.sav,使用Bootstrap法估计心率均值、标准差、中位数以及四分位间距(IQR)的95%置信区间。
本例使用频率对话框计算统计量,计算方式可以参考 小节 3.4.1 (使用频率对话框计算) 的操作,请先参考该部分讲义完成以下操作:
- 将变量从变量源列表移动到变量一栏
- 设置需要计算的统计量
接下来主要讲如何加上Bootstrap操作。
在频率对话框中( 图 3.4 )点击Bootstrap…按钮即可打开Bootstrap操作对话框
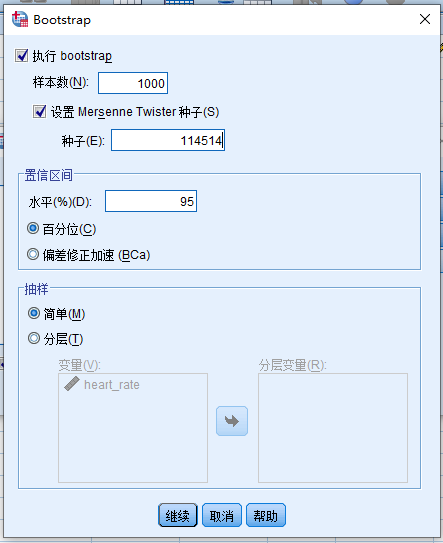
- 图中的样本数不是我们平常说的样本量,而是重复抽样的次数,保持1000即可
- 因为Bootstrap重复抽样是随机运算,每次计算的结果都会有一点不同。如果要保持可复现性,可以选择设置Mersenne Twister 种子成某个数值。一般来说不需要做这个设置
- 置信区间列表:
- 水平:可以保持使用95,如果要求99%置信区间,这里改成99就可以
- 百分位 还是 偏差修正加速:一般选用百分位
- 抽样列表:
- 选择简单
- 如果重复抽样的过程中要考虑一些协变量,可以在这里设置分层变量
- 点击继续
回到 图 3.4 界面后点击粘贴获取语法代码:
语法代码 5.1: 简单形式的Bootstrap
BOOTSTRAP
/SAMPLING METHOD=SIMPLE
/VARIABLES INPUT=heart_rate
/CRITERIA CILEVEL=95 CITYPE=PERCENTILE NSAMPLES=1000
/MISSING USERMISSING=EXCLUDE.
FREQUENCIES VARIABLES=heart_rate
/NTILES=4
/STATISTICS=STDDEV MEAN MEDIAN
/ORDER=ANALYSIS.代码块 5.1 前半段代码是Bootstrap的操作,而后半段(从FREQUENCIES开始)与 代码块 3.5 相同。
输出结果如下所示
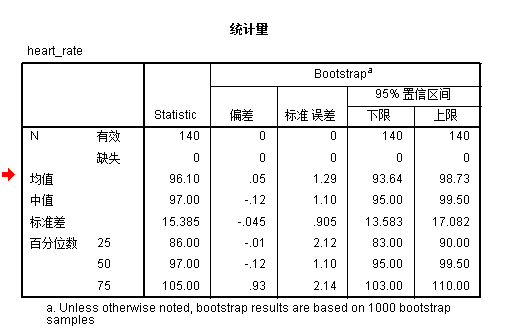
统计量(statistics)是不作bootstrap以前就有的,而Bootstrap则添加了后面几列。
5.1.2. Bootstrap + 探索
例4.2 打开数据文件bmi.sav,由于性别对于bmi会存在影响,请按照性别对bmi值进行分层重抽样,使用Bootstrap法估计存在冠心病与没有冠心病患者的bmi均值、标准差以及中位数的95%置信区间。
根据题目的要求,dis 是负责分组的
自变量,而性别则是
协变量。具体的操作方式如下:
- 参考 小节 3.4.2
(使用探索对话框计算)
中的做法,以
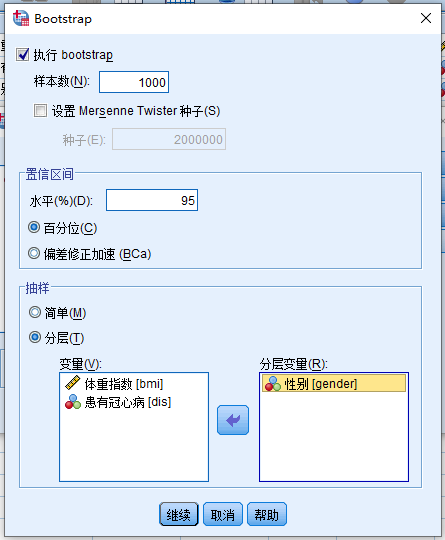
dis为因子,bmi为因变量。统计量对话框中选择描述性 - 点击Bootstrap,参考 小节 5.1.1
(Bootstrap + 频率)
。抽样列表中选择分层,以
gender为分层变量: 图 5.2
语法代码如下所示
语法代码 5.2: 探索中的Bootstrap应用
BOOTSTRAP
/SAMPLING METHOD=STRATIFIED(STRATA=gender )
/VARIABLES TARGET=bmi INPUT=dis
/CRITERIA CILEVEL=95 CITYPE=PERCENTILE NSAMPLES=1000
/MISSING USERMISSING=EXCLUDE.
EXAMINE VARIABLES=bmi BY dis
/PLOT BOXPLOT STEMLEAF
/COMPARE GROUPS
/STATISTICS DESCRIPTIVES
/CINTERVAL 95
/MISSING LISTWISE
/NOTOTAL.执行上述代码需要一定的时间,结果如下图所示
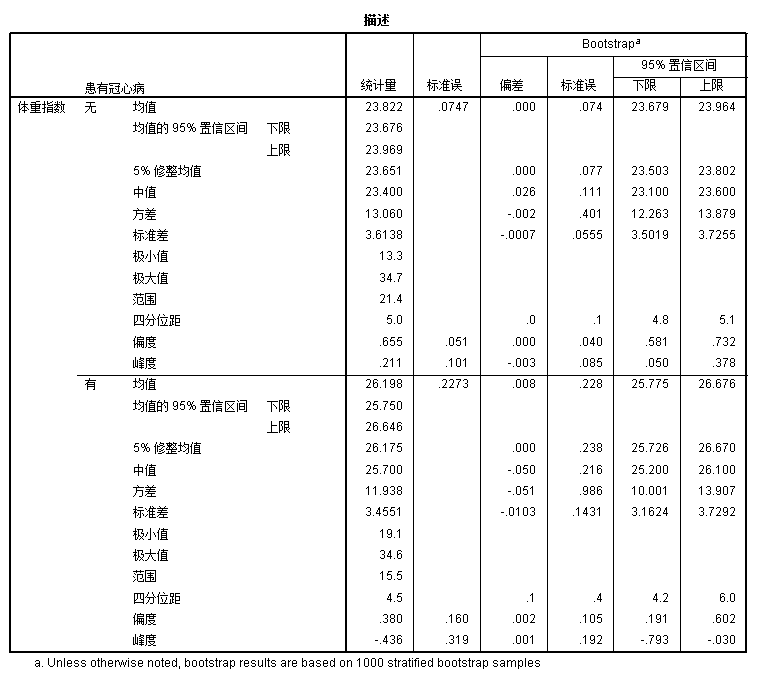
这其中,可以特别注意的是统计量一列的 均值的95%置信区间:(23.676-23.969) 与均值在Bootstrap中的下限与上限(23.679-23.964)是比较接近的。
5.2节. 单样本t检验
单样本t检验指的是从样本均值出发,在一个可以接受的一类错误概率下,对总体均值是否等于某个特定的值给出判断的工作。
例4.3 打开数据文件heart_rate.sav,并判断,在一类错误(\(\alpha\))为1%的情况下,样本所来自的总体,心率均值是否为100次/分钟?
菜单操作方式:
- 分析
- 比较均值
- 单样本t检验
- 比较均值
打开对话框:
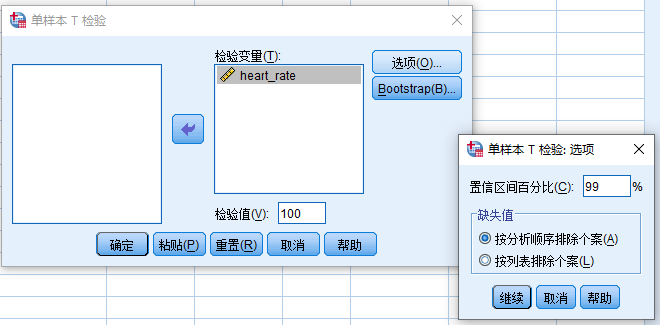
- 变量源列表 (heart_rate) > 检验变量
- 检验值:100
- 点击选项
- 置信区间百分比:填入99
- 点击继续
- 点击粘贴生成语法代码:
DATASET ACTIVATE 数据集2.
T-TEST
/TESTVAL=100
/MISSING=ANALYSIS
/VARIABLES=heart_rate
/CRITERIA=CI(.99).思考题:为什么要将置信区间百分比设置成99%?此外,可以看到t检验的对话框里也可以设置Bootstrap,但对于本问题而言,没有必要使用Bootstrap法估算均值的置信区间。
运行语法,输出结果如下图所示
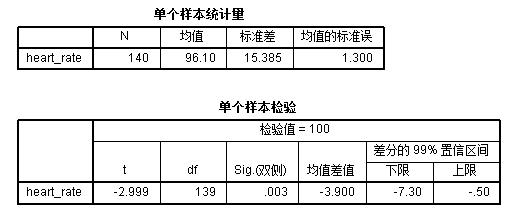
第一个表格展示了描述性统计的结果,包括均值、标准差两个重要的样本统计量,在填写三线表的时候需要采用\(均值\pm标准差\)的形式进行汇报。
第二个表格展示了t检验的统计结果,包括t值-2.999,自由度df=n-1为139,p值(写作sig):0.003,同时还给出了均值差值的99%置信区间。
这里需要说明一下,在理论课学习中,假设检验的工作流程是先设定一类错误\(\alpha\)的值,然后根据这个\(\alpha\)在统计表查找临界值(如\(t_{\alpha/2}\)),将计算出的t值与临界值对比再得出是否拒绝零假设的结论。但在统计学软件中,p值的计算虽然繁琐,但对于用户来说也就只是点几下鼠标而已。于是\(\alpha\)在假设检验流程中的作用就弱化了,仅仅在估计置信区间的时候才需要提供这一参数。
5.3节. 2配对样本t检验
例4.4 打开多时间点血压数据dbp.sav, 判断基线舒张压与30分钟后的舒张压是否存在差异?(一类错误\(\alpha\)为0.05)
菜单操作方式:
- 分析
- 比较均值
- 配对样本t检验
- 比较均值
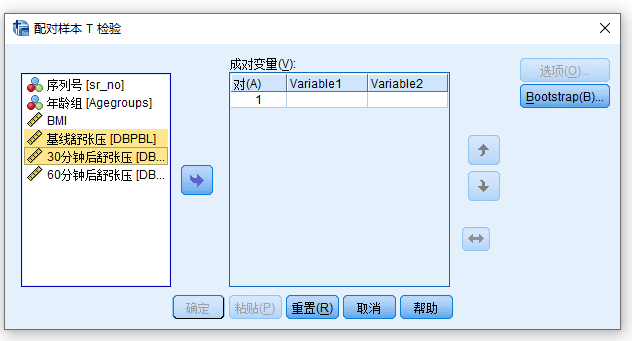
- 在变量源列表中点击DBPBL变量将其选中
- 按下键盘
CTRL键的同时,在变量源列表中点击DBPat30min变量将其一并选中 - 点击右向箭头将其加入 成对变量 列表
- 软件默认使用95%置信区间,无需点击选项按钮额外设置
- 点击粘贴生成语法代码
T-TEST PAIRS=DBPBL WITH DBPat30min (PAIRED)
/CRITERIA=CI(.9500)
/MISSING=ANALYSIS.运行语法生成结果如下图:
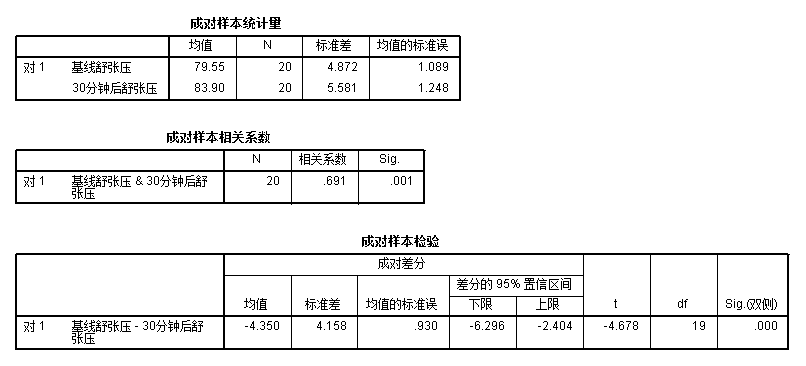
第一个表是描述性统计量,作用如前所述
第二个表是配对变量的相关性分析,目前暂予略过
第三个表是配对t检验的结果,包括差的均值、标准差,以及 \(t=\frac{d-0}{s}\),自由度,还有p值(sig)。其中差分的
95% 置信区间是指配对样本值之间的差值 \(\mu_d\) 置信区间。
5.4节. 2独立样本t检验
例4.5 打开数据bmi.sav, 比较患有冠心病与未患有冠心病人群的bmi是否存在差异(一类错误\(\alpha\)为0.01)
注:本例数据不符合正态分布,此处暂予忽略,仍进行t检验分析
菜单操作方式:
- 分析
- 比较均值
- 独立样本检验
- 比较均值
- 变量源列表 (bmi) > 检验变量
- 变量源列表 (disease) > 分组变量
- 点击定义组
- 选择使用指定值
- 组1:0
- 组2:1
- 点击继续
- 点击粘贴
语法如下:
T-TEST GROUPS=dis(0 1)
/MISSING=ANALYSIS
/VARIABLES=bmi
/CRITERIA=CI(.99).思考题:如果本题需要比较不同性别人群bmi是否存在差异,定义组的时候组1和组2各自应该填入什么值?
运行语法生成结果如下:
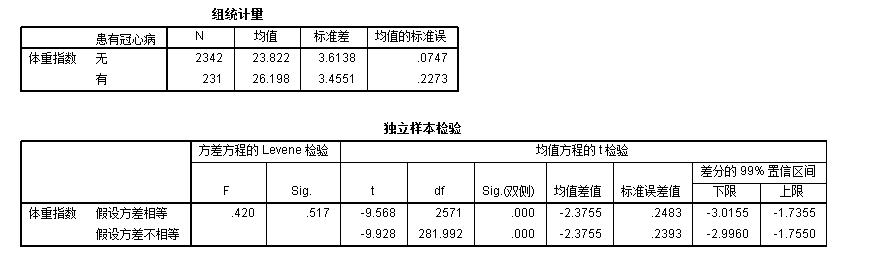
和前面两种t检验一样,第一个表是描述性统计量,第二个表是t检验结果。需要注意的是方差方程的Levene检验一项,如果该项检验的p值小于一类错误\(\alpha\),我们要认为2独立样本的方差齐性假设不被满足,因此必须采信假设方差不相等前提下得到的结论。也就是说,如果该项检验的p值大于\(\alpha\),独立样本t检验结果表格读取第一行的数据,否则,读取第二行的数据。
5.5节. 4.4 t检验结果的汇报
以 小节 5.4 (2独立样本t检验) 结果为例,可以使用三线统计表组织数据:

5.6节. 练习题
- 打开数据5_1.sav,数据为某市2010年男婴出生体重数据,1980年该市男婴平均出生体重为3.00 kg。
- 请分析该市2010年男婴出生体重均数与1980年是否不同?
- 请用Bootstrap法估算该市2010年男婴出生体重中位数的95%置信区间